|
REQ
|
Requirements Description
|
Protocol
|
|
350
|
6.2 Routing
areas
|
|
|
351
|
Within
the context of G.8080 a routing area exists within a single layer
network. A routing area is defined by
a set of subnetworks, the SNPP links that interconnect them, and the SNPPs
representing the ends of the SNPP links exiting that routing area. A routing area may contain smaller routing
areas interconnected by SNPP links.
The limit of subdivision results in a routing area that contains two
subnetworks and one link.
|
|
|
352
|
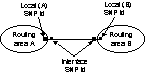
Where
an SNPP link crosses the boundary of a routing area, all the routing areas
sharing that common boundary use a common SNPP id to reference the end of
that SNPP link. This is illustrated in Figure 5.
|
|
|
353
|
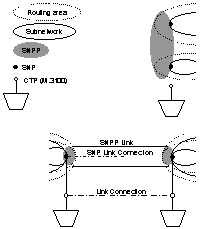
Figure 5/G.8080: Relationship
between routing areas, subnetworks, SNPs and SNPP
|
|
|
752
|
6.2.1 Aggregation of links
and Routing Areas
|
|
|
753
|
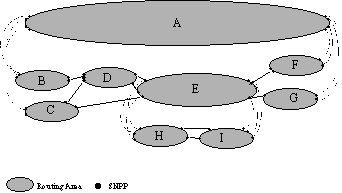
Figure 5.1/G.8080
illustrates the relationships between routing areas and subnetwork point
pools (SNPP links). Routing areas and SNPP links may be related
hierarchically. In the example routing area A is partitioned to create a
lower level of routing areas, B, C, D, E, F, G and interconnecting SNPP
links. This recursion can continue as many times as necessary. For example,
routing area E is further partitioned to reveal routing areas H and I. In the
example given there is a single top level routing area. In creating a
hierarchical routing area structure based upon "containment" (in
which the lower level routing areas are completely contained within a single
higher level routing area), only a subset of lower level routing areas, and a
subset of their SNPP links are on the boundary of the higher level routing
area. The internal structure of the lower level is visible to the higher
level when viewed from inside of A, but not from outside of A. Consequently
only the SNPP links at the boundary between a higher and lower level are
visible to the higher level when viewed from outside of A. Hence the
outermost SNPP links of B and C and F and G are visible from outside of A but
not the internal SNPP links associated with D and E or those between B and D,
C and D, C and E or between E and F or E and G. The same visibility applies
between E and its subordinates H and I. This visibility of the boundary between
levels is recursive. SNPP link hierarchies are therefore only created at the
points where higher layer routing areas are bounded by SNPP links in lower
level routing areas.
|
|
|
754
|
|
|
|
755
|
FIGURE 5.1/G.8080 Example of
a Routing Area Hierarchy and SNPP link Relationships
|
|
|
756
|
Subnetwork points are
allocated to an SNPP link at the lowest level of the routing hierarchy and
can only be allocated to a single subnetwork point pool at that level. At the
routing area hierarchy boundaries the
SNPP link pool at a lower level is fully contained by an SNPP link at a
higher level. A higher level SNPP link pool may contain one or more lower
level SNPP links. In any level of this hierarchy an SNPP link is associated
with only one routing area. As such routing areas do not overlap at any level
of the hierarchy. SNPP links within a level of the routing area hierarchy
that are not at the boundary of a
higher level may be at the boundary with a lower level thereby creating an
SNPP link hierarchy from that point (e.g. routing area E). This provides for
the creation of a containment hierarchy for SNPP links.
|
|
|
759
|
6.2.2 Relationship to Links
and Link Aggregation
|
|
|
760
|
A number of SNP link
connections within a routing area can be assigned to the same SNPP link if
and only if they go between the same two subnetworks. This is illustrated in
figure 5.2/G.8080. Four subnetworks, SNa, SNb, SNc and SNd and SNPP links 1,
2 and 3 are within a single routing area. SNP link connections A and B are in
the SNPP link 1. SNP link connections B and C cannot be in the same SNPP link
because they do not connect the same two subnetworks. Similar behaviourbehavior also applies
to the grouping of SNPs between routing areas.
|
|
|
762761
|
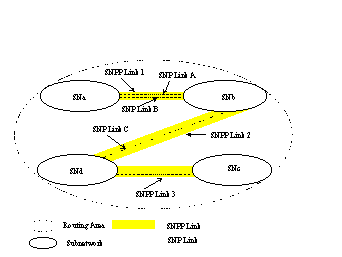
Figure 5.2/G.8080 SNPP link
Relationship to Subnetworks
|
|
|
766
|
SNP link connections between two routing areas, or
subnetworks, can be grouped into one or more SNPP links. Grouping into
multiple SNPP links may be required:
|
|
|
767
|
- if they are not equivalent for routing purposes
with respect to the routing areas they are attached to, or to the containing
routing area
|
|
|
768
|
- if smaller groupings are required for
administrative purposes.
|
|
|
769
|
There may be more than one routing scope to consider
when organizing SNP link connections into SNPP links. In Figure 5.4/G.8080, there
are two SNP link connections between routing areas 1 and 3. If those two routing areas are at the top
of the routing hierarchy (there is therefore no single top level routing
area), then the routing scope of RA-1 and RA-3 is used to determine if the SNP
link connections are equivalent for the purpose of routing.
|
|
|
770
|
The situation may however be as shown in Figure
5.4/G.8080. Here RA-0 is a containing routing area. From RA-0's point of
view, SNP link connections A&B could be in one (a) or two (b)SNPP links.
An example of when one SNPP link suffices is if the routing paradigm for RA-0
is step-by-step. Path computation sees no distinction between SNP link
connection A and B as a next step to get from say RA-1 to RA-2.
|
|
|
771
|
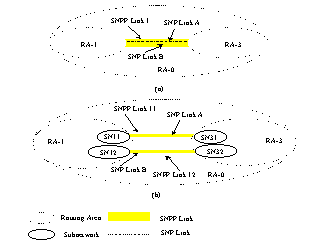
|
|
|
772
|
[Ed: See notes for Figure 5.2/G.8080. Same comments
apply to this figure.]
|
|
|
773
|
Figure 5.4/G.8080: Routing scope
|
|
|
774
|
From RA-1 and RA-3's point of view though, the SNP
link connections may be quite distinct from a routing point of view as
choosing SNP link connection A may be more desirable than SNP link connection
B for cost, protection or other reason. In this case, placing each SNP link
connection into its own SNPP link meets the requirement of "equivalent
for the purpose of routing". Note that in Figure 5.4/G.8080, SNPP link
11, Link 12 and Link 1 can all coexist.
|
|
|
780
|
Generally a control domain is derived from a
particular component type, or types, that interact for a particular purpose.
For example, routing (control) domains are derived from routing controller
components whilst a rerouting domain is derived from a set of connection
controller and network call controller components that share responsibility
for the rerouting/restoration of connections/calls that traverse that domain.
In both examples the operation that occurs, routing or rerouting, is
contained entirely within the domain. In this Recommendation control domains
are described in relation to components associated with a layer network.
|
|
|
781
|
As a domain is defined in terms of a purpose it is
evident that domains defined for one purpose need not coincide with domains
defined for another purpose. Domains of the same type are restricted in that
they may:
|
|
|
782
|
fully contain other domains of the same type,
but do not overlap,
|
|
|
783
|
border each other
|
|
|
784
|
be isolated from each other
|
|
|
832
|
6.2.10
Additional text for clause 8 Reference points
|
|
|
834
|
A
Reference Point represents a collection of services, provided via interfaces
on one or more pairs of components. The component interface is independent of
the reference point, hence the same interface may be involved with more than
one reference point. From the viewpoint of the reference point the components
supporting the interface are not visible, hence the interface specification
can be treated independently of the component.
|
|
|
835
|
The
information flows that carry services across the reference point are
terminated (or sourced) by components, and multiple flows need not be
terminated at the same physical location. These may traverse different
sequences of reference points as illustrated in Figure 29.1/G.8080)
|
|
|
836
|
Figure
29.1/G.8080: Reference points
|
|
|
354
|
6.3 Topology and discovery
Transport Topology is expressed to routing as SNPPs links
|
|
|
356
|
Link connections that are
equivalent for routing purposes are then grouped into links. This grouping is based on parameters, such
as link cost, delay, quality or diversity.
Some of these parameters may be derived from the server layer but in
general they will be provisioned by the management plane.
|
|
|
357
|
Separate Links may be
created (i.e., link connections that are equivalent for routing purposes may
be placed in different links) to allow the division of resources between
different ASON networks (e.g., different VPNs) or between resources
controlled by ASON and the management plane.
|
|
|
358-1
-2
-3
-4
-5
|
The link information (e.g.,
the constituent link connections and the names of the CTP pairs) is then used
to configure the LRM instances (as described in Section 7.3.3 of G.8080)
associated with the SNPP Link.
Additional characteristics of the link, based on parameters of the
link connections, may also be provided.
The LRMs at each end of the
link must establish a control plane adjacency that corresponds to the SNPP
Link.
The interface SNPP ids may
be negotiated during adjacency discovery or may be provided as part of the
LRM configuration.
The Link Connections and CTP
names are then mapped to interface SNP ids (and SNP Link Connection
names).
In the case where both ends
of the link are within the same routing area the local and interface SNPP id
and the local and interface SNP ids may be identical. Otherwise, at each end of the link the
interface SNPP id is mapped to a local SNPP id and the interface SNP ids are
mapped to local SNP ids. This is
shown in Figure 6.
|
|
|
359
|
Figure 6/G.8080:Relationship between local and
interface ids
|
|
|
362
|
Once the SNPP link
validation is completed by a discovery process, the LRMs informs the RC
component (see Section 7.3.2 of G.8080) of the SNPP Link adjacency and the
link characteristics e.g., cost, performance, quality and diversity.
|
|
|
791
|
6.4.1 Relationship between
control domains and control plane resources
|
|
|
792
|
The components of a domain
may, depending on purpose, reflect the underlying transport network
resources. A routing domain may, for example, contain components that
represent one or more routing areas at one or more levels of aggregation,
depending upon the routing method/protocol used throughout the domain. If a
routing domain contains more than one routing protocol the aggregation of
routing areas can be different for each routing protocol – reflecting
different views of the underlying resources.
|
|
|
799
|
6.5 Multi-layer aspects
|
|
|
800
|
The description of the
control plane can be divided into those aspects related to a single layer
network, such as routing, creation and deletion of connections, etc., and
those that relate to multiple layers. The client/server relationship between
layer networks is managed by means of the Termination and Adaptation
Performers. (see new Clause 7.3.7, below ) The topology and connectivity of
all of the underlying server layers is not explicitly visible to the client
layer, rather these aspects of the server layers are encapsulated and
presented to the client layer network as an SNPP link. Where connectivity
cannot be achieved in the client layer as a result of an inadequate resources
additional resources can only be created by means of new connections in one or more server layer networks, thereby
creating new SNP link connections in the client layer network. This can be
achieved by modifying SNPs from potential to available, or by adding more
infrastructure as an output of a planning process. The ability to create new
client layer resource by means of new connections in one or more server layer
networks is therefore a prerequisite to providing connectivity in the client
layer network. The model provided in this Recommendation allows this process
to be repeated in each layer network. The timescale at which server layer
connectivity is provided for the creation of client layer topology is subject
to a number of external constraints (such as long term traffic forecasting
for the link, network planning and financial authority) and is operator
specific. The architecture supports server layer connectivity being created
in response to a demand for new topology from a client layer by means of
potential SNPs which need to be discovered.
|
|
|
804
|
Protocol Controllers are
provided to take the primitive interface supplied by one or more
architectural components, and multiplex those interfaces into a single
instance of a protocol. This is described in Clause 7.4 and illustrated in
Figure 23/G.8080. In this way, a Protocol Controller absorbs variations among
various protocol choices, and the architecture remains invariant. One, or
more, protocol controllers are responsible for managing the information flows
across a reference point.
|
|
|
419
|
7.3.2 Routing Controller (RC) component
|
|
|
420
|
The role of the routing
controller is to:
|
|
|
421
|
-respond to requests from
connection controllers for path (route) information needed to set up
connections. This information can
vary from end-to-end (e.g., source routing) to next hop
|
|
|
422
|
-respond to requests for
topology (SNPs and their abstractions) information for network management
purposes
|
|
|
423
|
Information contained in the
route controller enables it to provide routes within the domain of its
responsibility. This information
includes both topology (SNPPs, SNP Link Connections) and SNP addresses (network
addresses) that correspond to the end system addresses all at a given
layer.
Addressing information about
other subnetworks at the same layer (peer subnets) is also maintained.
It may also maintain
knowledge of SNP state to enable constraint based routing.
Using this view, a possible
route can be determined between two or more (sets of ) SNPs taking into
account some routing constraints.
There are varying levels of
routing detail that span the
following:
|
|
|
424
|
- Reachability (e.g., Distance Vector view – addresses
and the next hops are maintained)
|
|
|
425
|
- Topological view (e.g.,Link State – addresses and topological position are
maintained)
|
|
|
426
|
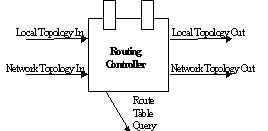
The routing controller has
the interfaces provided in Table 3 and illustrated in Figure 13.
|
|
|
427
|
Table 3/G.8080: Routing
controller interfaces
|
Input
Interface
|
Basic
Input
Parameters
|
Basic Return
Parameters
|
|
Route Table Query
|
Unresolved route element
|
ordered list of SNPPs
|
|
Local Topology In
|
Local topology update
|
|
|
Network Topology In
|
Network topology update
|
-
|
|
|
|
|
|
|
Output
Interface
|
Basic
Output
Parameters
|
Basic Return
Parameters
|
|
Local Topology Out
|
Local topology update
|
|
|
Network Topology Out
|
Network topology update
|
-
|
|
|
|
|
|
|
|
|
|
428
|
Figure 13/G.8080: Routing Controller Component
|
|
|
436
|
Local Topology interface:
This interface is used to configure the routing tables with local topology
information and local topology update information. This is the topology information that is within the domain of
responsibility of the routing controller.
|
|
|
437
|
Network Topology interface:
This interface is used to configure the routing tables with network topology
information and network topology update information. This is the reduced topology information
(e.g., summarized topology) that is outside the domain of responsibility of
the routing controller.
|
|
|
532-1
-2
-3
-4
|
7.4 Protocol Controller (PC)
Components
The Protocol Controller
provides the function of mapping the parameters of the abstract interfaces of
the control components into messages that are carried by a protocol to
support interconnection via an interface. Protocol Controllers are a sub
class of Policy Ports, and provide all the functions associated with those
components.
In particular, they report protocol violations to their monitoring
ports.
They may also perform the
role of multiplexing several abstract interfaces into a single protocol
instances as shown in Figure 23. The details of an individual protocol
controller are in the realm of protocol design, though some examples are
given in this Recommendation.
|
|
|
533
|
The role of a transport
protocol controller is to provide authenticated, secure, and reliable
transfer of control primitives across the network by means of a defined
interface. This permits transactions to be tracked and to ensure expected
responses are received, or that an exception is reported to the originator.
When security functions are present, the protocol controller will report
security violations via its monitoring port.
|
|
|
535
|
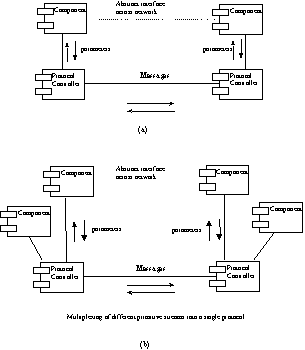
Figure 23/G.8080: (a) Generic use of a Protocol
Controller, (b) Generic multiplexing
of different primitive streams into a single protocol.
|
|
|
537
538
539
540
|
Examples of protocol
controller use is the transfer of the following information:
- Route table update
messages via a routing exchange protocol controller
- Link resource manager
coordination messages (where appropriate as in available bit rate
connections) via a link resource manager protocol controller;
- Connection control
coordination messages via a connection controller protocol controller. Note
that the LRM and CC coordination interfaces may be multiplexed over the same
protocol controller.
|
|
|
543
1512
|
7.5 Component Interactions
for Connection Setup
Three basic forms of
algorithm for dynamic path control can be distinguished, hierarchical, source
routing and step-by-step routing as shown in the following figures.
|
|
|
545
556-1
556-2
556-3
|
7.5.1 Hierarchical Routing
In the case of Hierarchical
Routing, as illustrated in Figure 25, a node contains a routing controller, connection
controllers and link resource managers for a single level in a subnetwork
hierarchy.
This uses the decomposition
of a layer network into a hierarchy of subnetworks (in line with the concepts
described in Recommendation G.805).
Connection controllers are
related to one another in a hierarchical manner.
Each subnetwork has its own
dynamic connection control that has knowledge of the topology of its
subnetwork but has no knowledge of the topology of subnetworks above or below
itself in the hierarchy (or other subnetworks at the same level in the
hierarchy).
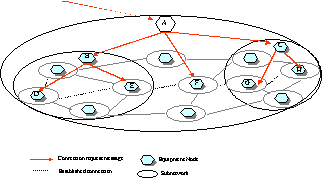
Figure 25/G.8080:
Hierarchical signalling flow
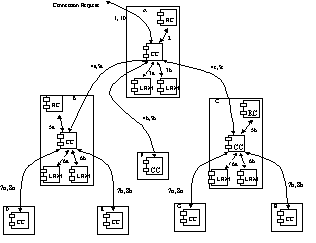
Figure 26/G.8080: Hierarchical Routing Interactions
In Figure 26, the detailed
sequence of operations involved in setting up a connection using hierarchic
routing is described below:
1. A connection request arrives at the Connection
Controller (CC), specified as a pair of SNPs at the edge of the subnetwork.
2. The Routing Component
(RC) is queried (using the Z end SNP) and returns the set of Links and
Subnetworks involved.
3. Link Connections are
obtained (in any order, i.e., 3a, or 3b in Figure 26) from the Link Resource
Managers (LRM).
4. Having obtained link
connections (specified as SNP pairs), subnetwork connections can be requested
from the child subnetworks, by passing a pair of SNPs. Again, the order of
these operations is not fixed, the only requirement being that link
connections are obtained before subnetwork connections can be created. The
initial process now repeats recursively.
|
|
|
558
|
7.5.2 Source and Step by
Step
While similar to
hierarchical routing, for source routing, the connection control process is
now implemented by a federation of distributed connection and routing
controllers. The significant difference is that connection controllers
operate on Routing Areas whereas they operate on subnetworks in the
hierarchical case. The signal flow for source (and step-by-step) routing is
illustrated in Figure 27.
|
|
|
559
|
In order to reduce the
amount of network topology each controller needs to have available, only that
portion of the topology that applies to its own routing area is made
available.
|
|
|
560
|
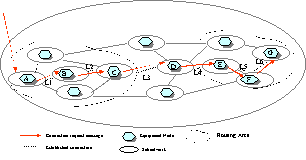
Figure 27/G.8080: Source and Step-by-step Signalling
flow
|
|
|
561
|
580
|
Source Routing
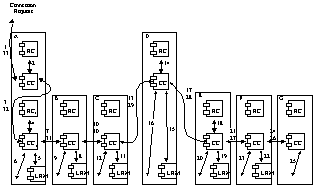
Figure 28/G.8080: Source Routing Interactions
In the following steps we
describe the sequence of interactions shown in Figure 28.
1. A connection request arrives at the Connection Controller
(CCA), specified as a pair of names (A and Z) at the edge of the subnetwork.
2. The Routing Component (RCA) is queried (using the Z end SNP)
and returns the egress link, L3.
3. As CCA does not have access to the necessary Link Resource
Manager (LRMC), the request (A, L3, Z) is passed on to a peer CCA1, which
controls routing through this Routing Area.
4. CCA1 queries RCA1 for L3 and obtains a list of additional
links, L1 and L2.
5. Link L1 is local to this node, and a link connection for L1 is
obtained from LRM A.
6. The SNC is made across the local switch (Controller not shown).
7. The request, now containing the remainder of the route (L2, L3
and Z), is forwarded to the next peer CCB.
8. LRM B controls L2, so a link connection is obtained from this
link.
9. The SNC is made across the local switch (Controller not shown).
10. The request, now containing the remainder
of the route (L3 and Z), is forwarded to the next peer CCC.
11. LRM C controls L3, so a link connection is
obtained from this link.
12. The SNC is made across the local switch
(Controller not shown).
13. The request, now containing the remainder
of the route (Z), is forwarded to the next peer CCD.
|
|
|
582
|
585
|
Step-By-Step Routing:
In this form of routing
there is further reduction of routing information in the nodes, and this
places restrictions upon the way in which routing is determined across the
sub-network. Figure 29 applies to the network diagram of Figure 27.
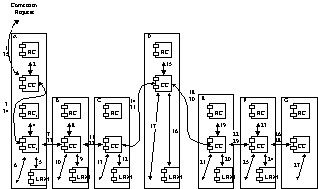
Figure 29/G.8080 Step-by-Step Routing
The process of step by step
routing is identical to that described for Source Routing, with the following
variation: Routing Controller RCA1 can only supply link L1, and does not
supply link L2 as well. CCB must then query RCB for L2 in order to obtain L2.
A similar process of obtaining one link at a time is followed when connecting
across the second Routing Area.
|
|
|
636
|
10 Addresses
|
|
|
637
|
Addresses are needed for
various entities in the ASON control plane, as described below:
|
|
|
638
|
UNI Transport Resource: The UNI SNPP Link requires an address for
the calling party call controller and network call controller to specify
destinations. These addresses must be
globally unique and are assigned by the ASON network. Multiple addresses may be assigned to the
SNPP. This enables a calling/called party to associate different applications
with specific addresses over a common link.
|
|
|
639
|
Network Call Control: The
Network Call Controller requires an address for signalling.
|
|
|
640
|
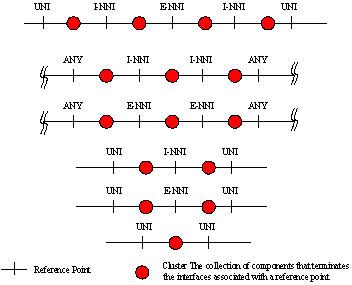
Calling/Called party Call
Control: The calling/called party
call controller requires an address for signalling. This address is local to a given UNI and is known to both the calling/called
party and network.
|
|
|
641
|
Subnetwork: A subnetwork is given an address
representing the collection of all SNPs on that subnetwork, which is used for
connection routing. The address is unique within the scope of an
administrative domain.
|
|
|
642
|
Routing Area: A routing area
is given an address representing the collection of all SNPPs on that routing
area, which is used for connection routing.
It is unique within the scope of an administrative domain.
|
|
|
643
|
SNPP: An SNPP is given an address used for
connection routing. The SNPP is part
of the same address space and scope as subnetwork addresses. See section 10.1 in amendment (Req. 852)
|
|
|
644
|
Connection controller: A
connection controller is given an address used for connection
signalling. These addresses are
unique within the scope of an administrative domain.
|
|
|
852
|
10.1 Name Spaces
|
|
|
853
|
There are three separate Transport names spaces in
the ASON naming syntax
|
|
|
854
|
1. A Routing Area name space.
|
|
|
855
|
2. A
subnetwork name space.
|
|
|
856
|
3. A link context name space.
|
|
|
857-1
857-2
|
The first two spaces follow the transport subnetwork
structure and need not be related.
Taken together, they define the topological point where an SNPP is
located.
The link context name space specifies within the SNPP
where the SNP is. It can be used to
reflect sub-SNPP structure, and different types of link names.
|
|
|
858
|
An SNPP name is a concatenation of:
|
|
|
859
|
one or more nested routing area names
|
|
|
860
|
an optional subnetwork name within the lowest routing
area level. This can only exist if
the containing RA names are present.
|
|
|
861
|
one or more nested resource context names.
|
|
|
862
|
Using this design, the SNPP name can recurse with
routing areas down to the lowest subnetwork and link sub-partitions (SNPP
sub-pools). This scheme allows SNPs
to be identified at any routing level.
|
|
|
863
|
SNP name: An SNP is given an address used for link
connection assignment and, in some cases, routing. The SNP name is derived
from the SNPP name concatenated with a locally significant SNP index.
|
|
|
872
|
11.2 Restoration
|
|
|
873-1
873-2
873-3
873-4
|
The restoration of a call is the replacement of a
failed connection by rerouting the call using spare capacity. In contrast to
protection, some, or all, of the SNPs used to support the connection may be
changed during a restoration event.
Control plane restoration occurs in relation to
rerouting domains. A rerouting domain is a group of call and connection
controllers that share control of domain-based rerouting.
The components at the edges of the rerouting domains
coordinate domain-based rerouting operations for all calls/connections that
traverse the rerouting domain.
A rerouting domain must be entirely contained within
a routing domain or area. A routing domain may fully contain several
rerouting domains. The network resources associated with a rerouting domain
must therefore be contained entirely within a routing area. Where a
call/connection is rerouted inside a rerouting domain, the domain-based
rerouting operation takes place between the edges of the rerouting domain and
is entirely contained within it.
|
|
|
874-1
874-2
874-3
|
The activation of a rerouting service is negotiated
as part of the initial call establishment phase.
For a single domain an intra-domain rerouting service
is negotiated between the source (connection and call controllers) and
destination (connection and call controller) components within the rerouting
domain.
Requests for an intra-domain rerouting service do not
cross the domain boundary.
|
|
|
875-1
875-2
875-3
|
Where multiple rerouting domains are involved the
edge components of each rerouting domain negotiate the activation of the
rerouting services across the rerouting domain for each call.
Once the call has been established each of the
rerouting domains in the path of the call have knowledge as to which
rerouting services are activated for the call. As for the case of a single
rerouting domain once the call has been established the rerouting services
cannot be renegotiated. This negotiation also allows the components
associated with both the calling and called parties to request a rerouting
service. In this case the service is referred to as an inter-domain service
because the requests are passed across rerouting domain boundaries.
Although a rerouting service can be requested on an
end-to-end basis the service is performed on a per rerouting domain basis
(that is between the source and destination components within each rerouting
domain traversed by the call).
|
|
|
876
|
During the negotiation of the rerouting services the
edge components of a rerouting domain exchange their rerouting capabilities
and the request for a rerouting service can only be supported if the service
is available in both the source and destination at the edge of the rerouting domain.
|
|
|
877
|
A hard rerouting service offers a failure recovery
mechanism for calls and is always in response to a failure event. When a link
or a network element fails in a rerouting domain, the call is cleared to the
edges of the rerouting domain. For a hard rerouting service that has been
activated for that call the source blocks the call release and attempts to
create an alternative connection segment to the destination at the edge of
the rerouting domain. This alternative connection is the rerouting connection.
The destination at the edge of the rerouting domain also blocks the release
of the call and waits for the source at the edge of the rerouting domain to
create the rerouting connection. In hard rerouting the original connection
segment is released prior to the creation of an alternative connection
segment. This is known as break-before-make. An example of hard rerouting is
provided in Figure 29.2/G.8080. In this example the routing domain is
associated with a single routing area and a single rerouting domain. The call
is rerouted between the source and destination nodes and the components
associated with them.
|
|
|
878
|
Soft rerouting service is a mechanism for the
rerouting of a call for administrative purposes (e.g. path optimisationoptimization, network
maintenance, and planned engineering works). When a rerouting operation is
triggered (generally via a request from the management plane) and sent to the
location of the rerouting components the rerouting components establish a
rerouting connection to the location of the rendezvous components. Once the
rerouting connection is created the rerouting components use the rerouting
connection and delete the initial connection. This is known as
make-before-break.
|
|
|
879
|
During a soft rerouting procedure a failure may occur
on the initial connection. In this case the hard rerouting operation
pre-empts the soft rerouting operation and the source and destination
components within the rerouting domain proceed according to the hard
rerouting process.
|
|
|
880
|
If revertive behaviourbehavior is required
(i.e. the call must be restored to the original connections when the failure
has been repaired) network call controllers must not release the original
(failed) connections. The network
call controllers must continue monitoring the original connections, and when
the failure is repaired the call is restored to the original connections.
|
|
|
881
|
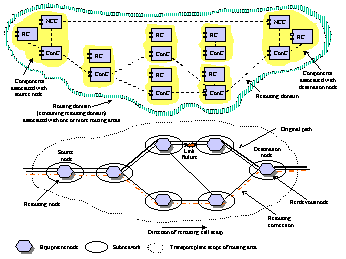
|
|
|
882
|
Figure 29.2/G.8080: Example of hard rerouting
|
|
|
883
|
11.2.1 Rerouting in response to failure
|
|
|
884
|
11.2.1.1 Intra Domain Failures
|
|
|
885
|
Any failures within a rerouting domain should result
in a rerouting (restoration) action within that domain such that any down
stream domains only observe a momentary incoming signal failure (or previous
section fail). The connections supporting the call must continue to use the
same source (ingress) and destination (egress) gateways nodes in the
rerouting domain.
|
|
|
886
|
11.2.1.2 Inter Domain Failures
|
|
|
887
|
Two failure cases must be considered, failure of a
link between two gateway network elements in different rerouting domains and
failure of inter-domain gateway network elements.
|
|
|
888
|
11.2.1.3 Link Failure between adjacent gateway
network elements
|
|
|
889
|
When a failure occurs outside of the rerouting
domains (e.g. the link between gateway network elements in different
rerouting domains A and B in Figure 29.3a/G.8080) no rerouting operation can
be performed. In this case alternative protection mechanisms may be employed
between the domains.
|
|
|
890
|
Figure 29.3b/G.8080 shows the example with two links
between domain A and domain B. The
path selection function at the A (originating) end of the call must select a
link between domains with the appropriate level of protection. The simplest
method of providing protection in this scenario is via a protection mechanism
that is pre-established (e.g. in a server layer network. Such a scheme is
transparent to the connections that run over the top of it). If the protected
link fails the link protection scheme will initiate the protection operation.
In this case the call is still routed over the same ingress and egress
gateway network elements of the adjacent domains and the failure recovery is
confined to the inter-domain link.
|
|
|
891
|
11.2.1.4 Gateway Network Element Failure
|
|
|
892
|
This case is shown in figure 29.4/G.8080. To recover
a call when B-1 fails a different gateway node, B-3, must be used for domain
B. In general this will also require the use of a different gateway in domain
A, in this case A-3. In response to the failure of gateway NE B-1 (detected
by gateway NE A-2) the source node in domain A, A-1, must issue a request for
a new connection to support the call. The indication to this node must
indicate that rerouting within domain A between A-1 and A-2 is to be avoided,
and that a new route and path to B-2 is required. This can be considered as
rerouting in a larger domain, C, which occurs only if rerouting in A or B
cannot recover the connection.
|
|
|
893
|
Figure 29.3/G.8080: Link failure scenarios 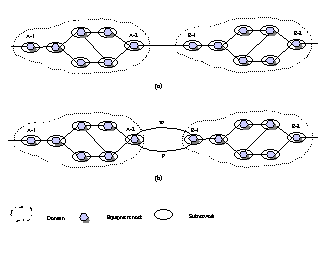
|
|
|
894
|
Figure 29.4/G.8080: Rerouting in event of a gateway
network element failure 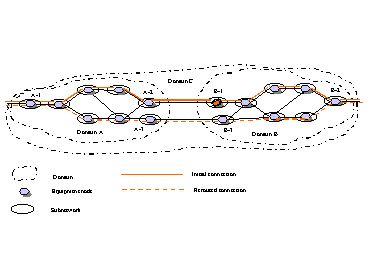
|
|
|
899
|
12.1 Principles of control and transport plane
interactions
|
|
|
904
|
Another principle of control and transport plane
interaction is that:
|
|
|
905
|
Existing connections in the transport plane are not
altered if the control plane fails and/or recovers. Control plane components are therefore dependent on SNC state.
|
|
|
915
|
12.2 Principles of Protocol Controller Communication
|
|
|
916
|
When communication between protocol controllers is
disrupted existing calls and their connections are not altered. The management plane may be notified if
the failure persists and requires operator intervention (for example, to
release a call).
|
|
|
997
|
II.2.3.1 Transport Plane Protection
|
|
|
1000
|
The Routing Controller must be informed of the
failure of a transport plane link or node and update the network/local
topology database accordingly. The Routing Controller may inform the local
Connection Controller of the faults.
|
|
|
1026
|
II.4.3 Routing Controller
|
|
|
1027
|
The failure of a Routing Controller will result in
the loss of new connection set-up requests and loss of topology database
synchronization. As the Connection
Controller depends on the Routing Controller for path selection, a failure of
the Routing Controller impacts the Connection Controller. Management plane
queries for routing information will also be impacted by a Routing Controller
failure.
|
|
|
1030
|
II.4.5
Protocol Controllers
|
|
|
1031
|
The
failure of any of the Protocol Controllers has the same effect as the failure
of the corresponding DCN signalling sessions as identified above. The failure
of an entire control plane node must be detected by the neighbouring nodes
NNI Protocol Controllers.
|
|
|
1513
|
5.1
Fundamental Concepts
|
|
|
1514
|
…Routing areas provide for
routing information abstraction, thereby enabling scalable routing
information representation. The service offered by a routing area (e.g., path
selection) is provided by a Routing Performer (a federation of Routing
Controllers), and each Routing Performer is responsible for a single routing
area. The RP
supports path computation functions consistent with one or more of the
routing paradigms listed in G.8080 (source, hierarchical and step-by-step)
for the particular routing area that it provides service for
|
|
|
1515
|
Routing areas may be
hierarchically contained and a separate Routing Performer is associated with
each routing area in the routing hierarchy. It is
possible for each level of the hierarchy to employ different Routing
Performers that support different routing paradigms. Routing Performers are realized through
the instantiation of possibly distributed Routing Controllers. The Routing Controller provides the
routing service interface, i.e., the service access point, as defined for the
Routing Performer. The Routing
Controller is also responsible for coordination and dissemination of routing
information. Routing Controller service
interfaces provide the routing service across NNI reference points at a given
hierarchical level. Different Routing
Controller instances may be subject to different policies depending upon the
organizations they provide services for.
Policy enforcement may be supported via various mechanisms; e.g., by
usage of different protocols.
|
|
|
1517
|
The relationship between the RA, RP, RC, and RCD
concepts is illustrated in Figure 1, below.
|
|
|
1518
|
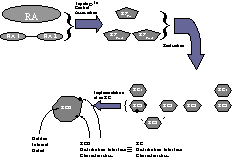
Figure 1/G.7715 –
Relationship between RA, RP, RC and RCD.
|
|
|
1519
|
As illustrated above,
routing areas contain routing areas that recursively define successive
hierarchical routing levels. A
separate RP is associated with each routing area. Thus, RPRA is
associated with routing area RA, and Routing Performers RPRA.1 and
RPRA.2 are associated with
routing areas RA.1 and RA.2, respectively. In turn, the RPs themselves are
realized through instantiations of distributed RCs RC1 and RC2, where the
RC1s are derived from RPRA and the RC2s are derived from Routing
Performers RPRA.1 and RPRA.2 , respectively. It may be seen that the
characteristics of the RCD distribution interfaces and the RC distribution
interfaces are identical.
|
|
|
2000
|
-
Provide
an equivalency functional placements of routing controllers, routing areas,
routing performers RA Ids, RC Ids, RCDs, etc.
|
|
|
1520
|
5.2 Routing
Architecture and Functional Components
|
|
|
1521
|
The routing architecture
has protocol independent components (LRM, RC), and protocol specific
components (Protocol Controller). The Routing Controller handles abstract
information needed for routing. The Protocol Controller handles protocol
specific messages according to the reference point over which the information
is exchanged (e.g., E-NNI, I-NNI), and passes routing primitives to the
Routing Controller. An example of routing functional components is
illustrated in Figure 2.
|
|
|
1522
|
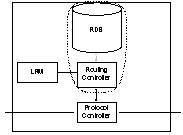
Figure 2/G.7715 - An Example of Routing Functional
Components
|
|
|
1523
|
|
|
|
1524
|
|
|
|
1528
|
5.2.1 Considerations for Different Protocols
|
|
|
1529
|
For a given Routing Area, there may be several
protocols supported for routing information exchange. The routing
architecture allows for support of multiple routing protocols. This is achieved by instantiating
different protocol controllers. The
architecture does not assume a one-to-one correspondence between Routing
Controller instances and Protocol Controller instances.
|
|
|
1535
|
5.2.3 Considerations for
Policy
|
|
|
1536
|
Routing policy enforcement
is achieved via the policy and configuration ports that are available on the
RC component. For a traffic
engineering application, suitable configuration policy and path selection
policy can be applied to RCs through those ports. This may be used to affect what routing information is revealed
to other routing controllers and what routing information is stored in the
RDB.
|
|
|
1537
|
5.3 Routing Area Hierarchies
|
|
|
1538
|
An example of
a routing area is illustrated in Figure 6 below. The higher level (parent) routing area RA
contains lower level (child) routing areas RA.1, RA.2 and RA.3. RA.1 and RA.2 in turn further contain
routing areas RA.1.x and RA.2.x.
|
|
|
1539
|
Figure
6/G.7715 –
Example of Routing Area Hierarchies
|
|
|
1542
|
5.3.1 Routing Performer Realization in
relation to Routing Area Hierarchies
|
|
|
1543
|
The
realization of the RP is achieved via RC instances. As described in G.8080,
an RC encapsulates the routing information for the routing area, and provides
route query services within the area, at that specific level of the
hierarchy. In the context of
hierarchical routing areas, the realization of the hierarchical RPs is
achieved via a stack of RC instances, where each level of the stack corresponds
to a level in the hierarchy.
|
|
|
1544
|
At a given hierarchical level, depending
upon the distribution choices two cases arise:
-
Each of the distributed Routing
Controllers could encapsulate a portion of the overall routing information
database.
-
Each of the distributed Routing
Controllers could encapsulate the entire routing information database
replicated via a synchronization mechanism.
|
|
|
1546
|
Note – The special
case of a centralized implementation is represented by a single instance of a
Routing Controller. (For the purposes
of resilience there may be a standby as well.)
|
|
|
1548
|
In the context of interactions between
Routing Controllers at different levels of the hierarchy, it is important to
note that information received from the parent RC shall not be circulated
back to the parent RC.
|
|
|
1555
|
6 ASON Routing Requirements
|
|
|
1556
|
ASON routing
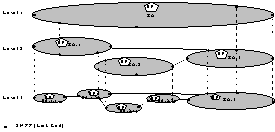
requirements include architectural, protocol and path computation
requirements.
|
|
|
1557
|
6.1 Architectural Requirements
|
|
|
1558
|
-
Information
exchanged between routing controllers is subject to policy constraints
imposed at the reference points.
To
what extent, if any, does this protocol require or prohibit sharing of
information between two routing controllers.
|
|
|
1559
|
A routing performer operating at any level of
hierarchy should not be dependent upon the routing protocol(s) that are being
used at the other levels.
|
|
|
1560
|
The routing information exchanged between
routing control domains is independent of intra-domain protocol choices.
|
|
|
1561
|
The routing information exchanged between
routing control domains is independent of intra-domain control distribution
choices, e.g., centralized, fully-distributed.
|
|
|
1562
|
The routing adjacency topology and transport
network topology shall not be assumed to be congruent.
|
|
|
1563
|
Each routing area shall be uniquely
identifiable within a carrier’s network.
|
|
|
1564
|
The routing information shall support an
abstracted view of individual domains. The level of abstraction is subject to
operator policy.
|
|
|
1565
|
The RP shall provide a means for recovering
from system faults (e.g., memory exhaust).
|
|
|
1567
|
The
routing protocol shall be capable of supporting multiple hierarchical levels
as defined in G.7715
|
|
|
1568
|
The routing protocol shall support
hierarchical routing information dissemination including summarized routing
information.
|
|
|
1569
|
The routing protocol shall include support
for multiple links between nodes and shall allow for link and node diversity.
|
|
|
1570
|
The routing protocol shall be capable of
supporting architectural evolution in terms of number of levels of hierarchies, aggregation and
segmentation of domains.
|
|
|
1571
|
The routing protocol shall be scalable with
respect to the number of links, nodes, and routing area hierarchical levels.
|
|
|
1572
|
In response to a routing event (e.g.,
topology update, reachability update) the contents of the RDB shall converge
and a proper damping mechanism for flapping (chattering) shall be provided.
|
|
|
1573
|
The routing protocol shall support or may
provide add-on features for supporting a set of operator-defined security
objectives where required.
|
|
|
1575
|
6.3 Path Selection Requirements
|
|
|
1577
|
Path selection shall support at least one of
the routing paradigms described in G.8080; i.e., hierarchical, source, and
step-by-step.
|
|
|
1579
|
7
Routing Attributes
|
|
|
1583
|
7.1
Node Attributes
|
|
|
1585
|
7.1.1
Reachability Attributes
|
|
|
1586
|
The routing protocol shall allow a node to
advertise the end-points reachable through that node. This is typically
shared via an explicit or summarized list of addresses. The reachability address prefix may
include as an attribute the path information from where the reachability
information is injected to the destination. Addresses are associated with
SNPPs and subnetworks.
|
|
|
1588
|
The routing protocol shall allow a node to
advertise the diversity related attributes that are used for constrained path
selection. One example is the Shared Risk Group (see Appendix II for more
information). This attribute, which
can be a list of individual node shared risk group identifiers, is used to
identify those nodes subject to similar fates.
Another example constraint might be related to
exclusion criteria (e.g., non-terrestrial nodes, geographic domains),
inclusion criteria (e.g., nodes with dual-backup power supplies).
|
|
|
1594
|
7.2 Link
Attributes
|
|
|
1595
|
The protocol shall minimally support the set of
link attributes related to link state and diversity. The negotiation of link
policy, e.g. glare resolution, is out of scope of the routing function.
The routing protocol shall not be burdened with
the negotiation of link policy, e.g., contention resolution, which is out of
scope of the routing function.
|
|
|
1597
to|
1601
|
The link state attribute shall support at least
the following:
Link State is a triplet comprised of existence,
weight and capacity:
·
Existence
The most fundamental link attribute is that which indicates the
existence of a link between two different nodes in the Routing Information
Database. From such information the basic topology (connectivity) is
obtained. The existence of the link
does not depend upon the link having an available capacity (e.g., the link
could have zero capacity because all link connections have failed).
·
Link Weight
The link weight is an attribute resulting from the
evaluation of possibly multiple metrics as modified by link policy or
constraint. Its value is used to indicate the relative desirability of a
particular link over another during path selection/computation
procedures. A higher value of a link
weight has traditionally been used to indicate a less desirable path. It may also be used for preventing use of
links where the capacity is nearly exhausted by changing the value of the
link weights.
·
Capacity
For a given layer network, this information is
mainly concerned with the number of Link Connections on a link. The amount of
information to disseminate concerning capacity is an operator policy
decision. For example, for some
applications it may suffice to reveal that the link has capacity to accept
new connections while not revealing the amount of capacity that is available,
while other applications may require the revealing of the available
capacity. A consequence of not
revealing more information concerning capacity is that it becomes harder to
optimize the usage of network resources.
|
|
|
1606
|
8 Routing Messages
|
|
|
1608
1613
|
The routing protocol shall support a set of
maintenance messages between the protocol controllers to maintain a logical
routing adjacency established dynamically or via manual configuration. The
scope of message exchange is normally confined to the PCs that form the
adjacency.
Routing adjacency refers to the logical
association between two routing controllers and the state of the adjacency is
maintained by the protocol controllers after the adjacency is established. As
the adjacency changes its state, appropriate events are sent to the routing
controllers by the protocol controllers. The events are used by the routing
controller to control the transmission of routing information between the
adjacent routing controllers.
|
|
|
1612
|
8.1 Routing Adjacency Maintenance
|
|
|
1614
|
1618
|
The protocol shall support the following set of
routing adjacency maintenance events:
-
RAdj_CREATE:
Indicates an new adjacency has been initiated.
-
RAdj_DELETE:
Indicates an adjacency has been removed.
-
RAdj_UP:
Indicates a bi-directional adjacency has been established.
-
Radj_DOWN: Indicates bi-directional adjacency has been down.
|
|
|
1624
|
1628
1632
|
The routing protocol shall
support a set of abstract messages of the forms listed below:
-
RI_RDB_SYNC:
These messages help to synchronize the entire routing information database
between two adjacent routing controllers.
This is done at initialisation and may also be done periodically.
-
RI_ADD:
Once a new network resource has been added, the routing information related
to that resource would be advertised using this message in order to be added
into the RDB.
-
RI_DELETE:
Once an existing network resource has been deleted, the routing information
related to that resource should be withdrawn from the RDB.
-
RI_UPDATE:
Once the routing information of an existing network resource is changed, the
new routing information related to that resource is re-advertised in order to
update the RDB.
-
RI_QUERY:
When needed, an RC can send a route query message to its routing adjacency
neighbour for the routing information related to a particular route.
-
RE_NOTIFY:
This message will be generated when an error or exception condition is
encountered during the routing process.
|
|
|
1636
|
1642
|
The protocol shall be able to support the behaviourbehavior illustrated
in the following figure when transmitting the information element.
The state machine illustrated below deals with the
transmission of routing Information Elements (IE) from a Routing Controller
across a routing adjacency to a peer Routing Controller. Throughout the
message exchange, it is assumed that the Protocol Controller will provide for
the reliable delivery of the transmitted information. One instance of this
state machine exists for each Routing Adjacency that is being maintained by
the Protocol Controller state machine.
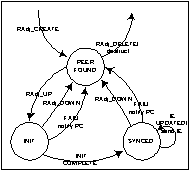
Figure 11/G.7715 - Routing IE
Transmission State Diagram
The
Routing Controller creates an instance of the state machine when a Protocol
Controller identifies a new Routing Adjacency. This is done upon receipt of a
RAdj_CREATE event. Initially, the state machine will be in the <PEER
FOUND> state. This state exists as
a "holding state" until the Protocol Controller identifies the
Routing Adjacency as being up. If the
Protocol Controller identifies that the routing adjacency no longer exists,
then this instance of the state machine is destroyed.
Upon
receipt of RAdj_UP event, the state
machine will enter the <INIT> state. In this state, the Routing
Controller will start the synchronization of the local RDB with the remote
RDB.
After
the Routing Adjacency has been initialisedinitialized, the State Machine will enter
the <SYNCED> state. While in this state, the local Routing Controller
will be notified of changes made to the RDB. When a change occurs, an
incremental routing update will be sent to the peer Route Controller.
If
the routing adjacency at anytime ceases to be bi-directional, the Protocol
Controller sends a RAdj_DOWN event and the state machine will return to the
<PEER FOUND> state.
|
|
|
1643
|
8.4.2
Information Element Reception
|
|
|
1644
|
1650
|
The protocol shall be able to support the behavior
illustrated in the following figure, when receiving an Information Element.
The state machine described below deal with the
reception of Information Elements from a Routing Controller across a routing
adjacency to a peer Routing Controller.
A single copy of this state machine exists for each Routing
Controller.
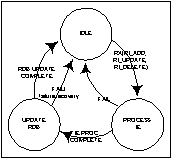
Figure 12/G.7715-
Routing IE Reception State Diagram
At the time the routing IE Reception State Machine
is initialised, the State Machine will be placed into the IDLE state.
Upon receipt of an RI_ADD, RI_UPDATE, or RI_DELETE
message from a peer Routing Controller, the Routing Controller transitions to
the <PROCESS IE> state. In this
state, the Routing Controller will perform operations on the Information
Element to make the information suitable for inclusion into the RDB.
An IE PROC COMPLETE event indicates that the
protocol specific processing has been completed, causing the State Machine to
submit the IE to the RDB for update based on the Information Element's
contents and enters the <UPDATE RDB> state. New information regarding nodes or links will be added to the
RDB. Changes to the attributes associated with nodes or links already in the
RDB will be handled as an update to the RDB.
Likewise, the Information element can direct the Routing Controller to
remove a node or link from the RDB.
When
the RDB update is complete, an UPDATE COMPLETE event will be received,
causing the State Machine to return to the <IDLE> state, where the
system will await the reception of another Information Element.
|
|
|
1651
|
8.4.3 Local Information Element Transmission
Generation
|
|
|
1652
|
1659
|
The protocol shall be able to support the behaviourbehavior illustrated
in the following figure.
The state machine illustrated below deal with the
Information Elements generated by the RC based on information received from
an associated Link Resource Manager. One instance of this state machine
exists for each locally generated Information Element the state machine.
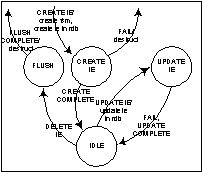
Figure
13/G.7715-
Local Information Generation State Diagram
As the Routing Controller receives information
from an associated Link Resource Manager, the Routing Controller will
identify the need to create a new Information Element. As a result, the Routing Controller will
create a new instance of the Local Information Generation State Machine,
submit the new information element to the RDB, and transition to the
<UPDATE IE> state.
When the Information Element has been stored in
the RDB, an UPDATE COMPLETE event will be generated. This will cause the State Machine to enter
the <IDLE> state, where it will wait for either a request for an update
to the Information Element or for a request to delete the Information
Element.
When the Routing Controller receives an UPDATE
event, the State Machine will send the update information to the RDB, and
again transition to the <UPDATE IE> state. As with the creation event, when the RDB has been successfully
updated an UPDATE COMPLETE event will be generated, causing the state machine
to transition to the IDLE state.
When the Routing Controller receives a DELETE
event, the Information Element will need to be deleted from the RDB.
Consequently, a flush operation is invoked, and the state machine transitions
to the <FLUSH> state.
When
the flush is complete, the state machine will receive a FLUSH COMPLETE event,
and the Routing Controller will destroy the state machine. When the flush is
complete, the state machine will receive a FLUSH COMPLETE event, and the
Routing Controller will destroy the state machine.
|
|
|
1660
|
9
Routing Message Distribution Topology
|
|
|
1661
|
When the Routing Performer for a routing area is
realized as a set of distributed Routing Controllers, information regarding
the network topology and reachable endpoints needs to be disseminated to, and
coordinated with, all other Routing Controllers. The method used to pass
routing information between peer Routing Controllers is independent of the
location of the source and the user of the information.
Consequently a routing protocol may support
separation of the distribution topology from the transport topology being
described. Characterize the dependency between these two topologies in terms
of protocol behaviourbehavior, e.g., protocol does/does not
require “congruent topology”.
|
|
|
1662
|
TITLE: G.7715.1
ASON Routing Architecture and Requirements for Link-State Protocols
|
|
|
1663
|
Summary
|
|
|
1664
|
This draft new Recommendation G.7715.1 “ASON
Routing Architecture and Requirements for Link-State Protocols” provides
requirements for a link-state instantiation of G.7715 . A link-state G.7715 routing instantiation
supports both hierarchical and source routed path computation functions.
|
|
|
1665
|
1 Introduction
|
|
|
1666
|
This recommendation provides of a mapping from
the relevant ASON components to distributed link state routing
functions. The mapping is one
realization of ASON routing architecture.
|
|
|
1667
|
Recommendations G.807 and G.8080 together specify
the requirements and architecture for a dynamic optical network in which
optical services are established using a control plane. Recommendation G.7715 contains the detailed
architecture and requirements for routing in ASON, which in conjunction with the routing architecture defined in
G.8080 allows for different implementations of the routing functions. It should be noted that the various
routing functions can be instantiated in a variety of ways including
distributed, co-located, and centralized mechanisms.
|
|
|
1668
|
Among different link-state attributes defined
within this document, support of hierarchical routing levels is defined as a
key element built into this instantiation of G.7715 by the introduction of a
number of hierarchy-related attributes.
This document complies with the requirement from G.7715 that routing
protocols in different hierarchical levels do not need to be homogeneous.
|
|
|
1669
|
As described in G.807 and G.8080, the routing
function is applied at the I-NNI and E-NNI reference points and supports the
path computation requirements of connection management at those same
reference points. Support of packet
forwarding within the control plane using this routing protocol is not in the
scope of this recommendation.
|
|
|
1670
|
2 References
|
|
|
1671
|
ITU-T Rec. G.7713/Y.1704 (2001), Distributed
Connection Management (DCM)
|
|
|
1672
|
ITU-T Rec. G.803 (2000), Architecture of
Transport Networks based on the Synchronous Digital Hierarchy
|
|
|
1673
|
ITU-T Rec. G.805 (2000), Generic Functional
Architecture of Transport Networks
|
|
|
1674
|
ITU-T Rec. G.807/Y.1301 (2001), Requirements for
the Automatic Switched Transport Network (ASTN)
|
|
|
1675
|
ITU-T Rec. G.8080/Y.1304, Architecture of the
Automatic Switched Optical Network (ASON)
|
|
|
1676
|
ITU-T Rec. G.7715/Y.1706 “Architecture and
Requirements for Routing in the Automatically Switched Optical Network”
|
|
|
1677
|
3 Definitions
|
|
|
1678
|
RA - RA (G.8080)
|
|
|
1679
|
RP - Routing Performer (G.7715)
|
|
|
1680
|
RC - Routing Controller (G.8080)
|
|
|
1681
|
RCD - Routing Control Domain (G.7715)
|
|
|
1682
|
RDB - Routing Database (G.7715)
|
|
|
1683
|
RA ID - RA Identifier
|
|
|
1684
|
RC ID - RC Identifier
|
|
|
1685
|
RCD ID - RCD Identifier
|
|
|
1686
|
4 Abbreviations
|
|
|
1687
|
LRM - Link Resource Manager (G.8080)
|
|
|
1688
|
TAP – Termination and Adaptation Performer
|
|
|
1689
|
5 A
G.7715 Link State Mapping
|
|
|
1690
|
The routing architecture defined in G.8080 and
G.7715 allows for different distributions of the routing functions. These may be instantiated in a variety of
ways such as distributed, co-located, and centralized.
|
|
|
1691
|
Characteristics of the routing protocol described
in this document are:
|
|
|
1692
|
1. It is a link state routing protocol.
|
|
|
1693
|
2. It operates for multiple layers.
|
|
|
1694
|
3. It is hierarchical in the G.7715 sense. That is, it can participate in a G.7715
hierarchy. This hierarchy follows
G.805 subnetwork structure through the nesting of G.8080 RAs.
|
|
|
1695
|
4. Source routed path computation functions may be
supported. This implies that topology
information necessary to support source routing must be made available.
|
|
|
1696
|
The choice of source routing for path computation
has some advantages for supporting connection management in transport
networks. It is similar to the manner
in which many transport network management systems select paths today.
|
|
|
1697
|
To accommodate these characteristics the
following instantiation of the G.7715 architecture is defined. Hence a compliant link-state routing
protocol is expected to locate and assign routing functions in the following
way:
|
|
|
1698
|
1. In a given RA, the RP is composed by a set of
RCs. These RCs co-operate and
exchange information via the routing protocol controller.
|
|
|
1699
|
2. At the lowest level of the hierarchy, each matrix
has a corresponding RC that performs topology distribution. At different levels of the hierarchy RCs
representing lower areas also perform topology distribution within their
level.
|
|
|
1700
|
3. Path computation functions may exist in each RC,
on selected RCs within the same RA, or could be centralized for the RA. Path computation on one RC is not
dependent on the RDBs in other RCs in the RA. If path computation is centralized, any of the RDBs in the RA
(or any instance) could be used.
|
|
|
1701
|
4. The RDB is replicated at each RC within the same area,
where the RC uses a distribution interface to maintain synchronization of the
RDBs.
|
|
|
1702
|
5. The RDB may contain information about multiple
layers.
|
|
|
1703
|
6. The RDB contains information from higher and
lower routing levels
|
|
|
1704
|
7. The protocol controller is a single type (link
state) and is used to exchange information between RCs within a RA. The protocol controller can pass
information for multiple layers and conceptually interact with various RCs at
different layers. Layer information
is, however, not exchanged between RCs at different layers.
|
|
|
1705
|
8. When a protocol controller is used for multiple
layers, the LRMs that are associated with the protocol controllers for every
RCs (i.e. only those it interacts with) must share a common TAP. This means that the LRMs share a common
locality.
|
|
|
1706
|
The scenario where an RC does not have an
associated path computation function may exist when there are no UNIs
associated with that RC, i.e., no connection controller queries that RC.
|
|
|
1707
|
6 Identification
of components and hierarchy
|
|
|
1708
|
It must be possible to distinguish between two
RCs within the same RA, therefore requiring a RC identifier (RC ID). It
should be noted that the notion of a RCD identifier is equivalent to that of
an RC ID.
|
|
|
1709
|
Before two RCs start talking to each other they
should check that they are in the same RA , particularly when a hierarchical
network is assumed. Therefore an identifier for the RA is also defined (RA
ID) to define the scope within which one or more RCs may participate.
|
|
|
1710
|
Both RC-ID and RA-ID are separate concepts in a
hierarchical network. However, as the RA-ID is used to identify and work
through different hierarchical levels, RC-ID MUST be unique within its
containing RA. Such a situation is
shown in Error! Reference source not found. where the RC-IDs at hierarchy “level 2” overlap
with those used within some of the different “Level 1” RAs.
|
|
|
1711
|
Another distinction between RA identifiers and RC
identifiers is that RA identifiers are associated with a transport plane name
space whereas RC identifiers are associated with a control plane name space.
|
|
|
1712
|
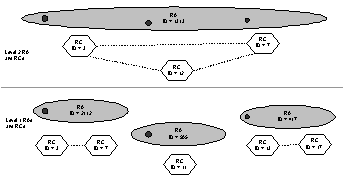
Figure 1. Example
network where RC identifiers within one RA are reused within another RA
|
|
|
1713
|
6.1 Operational
Issues arising from RA Identifiers
|
|
|
1714
|
In the process of running an ASON network, it is
anticipated that the containment relationships of RAs may need to change from
time to time motivated by unforeseen events such as mergers, acquisitions,
and divestitures.
|
|
|
1715
|
The type of operations that may be performed on a
RA include:
|
|
|
1716
|
- Splitting and merging
|
|
|
1717
|
- Adding a new RA between levels or at the top of
the hierarchy
|
|
|
1718
|
6.1.1 Splitting/Merging
areas
|
|
|
1719
|
Support for splitting and merging areas are best
handled by allowing a RA to have multiple synonymous RA identifiers.
|
|
|
1720
|
The process of splitting can be accomplished in
the following way:
|
|
|
1721
|
1. Adding the second identifier to all RCs that will
make up the new area
|
|
|
1722
|
2. Establishing a separate parent/child RC adjacency
for the new RA identifier to at least one route controller that will be in
the new area
|
|
|
1723
|
3. At a specified time, dropping the original RA
identifier from the nodes being placed in the new Route Area. This would be first one on the nodes that
are adjacent to the RCs that are staying in the old area.
|
|
|
1724
|
The process of merging can be accomplished in the
following way:
|
|
|
1725
|
1. The RA identifier for the merged area is selected
from the two areas being merged
|
|
|
1726
|
2. The RA identifier for the merged area is added to
the RCs in the RA being deprecated that are adjacent to RCs in the area that
the merged area identifier is taken from
|
|
|
1727
|
3. The RA identifier for the merged area is added to
all other RCs in the RA being deprecated
|
|
|
1728
|
4. The RA identifier for the merged area is added to
any parent/child RC adjacencies that are supporting the RA identifier being
deprecated
|
|
|
1729
|
5. The RA identifier being deprecated is now removed
from the RCs that came from the area being deprecated.
|
|
|
1730
|
AS mentioned above, a RA MUST be able to support
multiple synonymous RA Identifiers.
It must be ensured that before merging two areas, their RA Identifiers
are unique.
|
|
|
1731
|
6.1.2 Adding a new RA between levels or at the
top of the hierarchy
|
|
|
1732
|
Adding a new area at the top of the hierarchy or
between two existing areas in the hierarchy can be accomplished using similar
methods as those explained above for splitting and merging of RAs. However, the extent of reconfiguration
needed depends on how a RA is uniquely identified. Two different approaches exist for defining an RA identifier:
|
|
|
1733
|
1. RA identifiers are scoped by the containing
RA. Consequently, unique RA
"names" consist of a string of RAs identifiers starting at the root
of the hierarchy. The parent/child
relationship that exists between two RAs is implicit in the RA
"name".
|
|
|
1734
|
2. RA identifiers are global in scope. Consequently,
a RA will always uniquely be named by just using its RA identifier. The
parent/child relationship that exists between two RAs needs to be explicitly
declared.
|
|
|
1735
|
Since RCs need to use the RA Identifier to
identify if an adjacent RC is located in the same RA, the RA Identifier will need
to be known prior to bringing up adjacencies.
|
|
|
1736
|
If the first method is used, then insertion of a
new area will require all RCs in all areas below the point of insertion to
have the new RA identifier provisioned into it before the new area can be
inserted. Likewise, once the new area
has been inserted, the old RA identifier will need to be removed from the
configuration active in these RCs. As the point of insertion is moved up in
the hierarchy, the number of nodes that will need to be reconfigured will
grow exponentially.
|
|
|
1737
|
However, if RA identifiers are globally unique,
then the amount of reconfiguration is greatly reduced. Instead of all RCs in areas below the
point of insertion needing to be reconfigured, only the RCs involved in parent/child
relationships modified by the insertion need to be reconfigured.
|
|
|
1738
|
[Editor's Note: Replaced by new section 7 text]
|
|
|
1739
|
7 Addressing
|
|
|
1740
|
[Editor's Note: This section proposed to be added
with text derived from WD 23]
|
|
|
1741
|
The ASON Routing component has identifiers whose
values are drawn from several address spaces. Addressing issues that affect routing protocol requirements
include maintaining separation of spaces, understanding what other components
use the same space that routing uses, and what mappings are needed between
spaces.
|
|
|
1742
|
7.1 Address Spaces
|
|
|
1743
|
There are four broad categories of addresses used
in ASON.
|
|
|
1744
|
1. Transport plane addresses. These describe G.805 resources and
multiple name spaces can exist to do this.
Each space has an application that needs a particular organization or
view of those resources, hence the different address spaces. For routing, there are two spaces to consider:
|
|
|
1745
|
a. SNPP addresses.
These addresses give a routing context to SNPs and were introduced in
G.8080. They are used by the control
plane to identify transport plane resources.
However, they are not control plane addresses but are a (G.805) recursive
subnetwork context for SNPs. The
G.8080 architecture allows multiple SNPP names spaces to exist for the same
resources. An SNPP name consists of a
set of RA names, an optional subnetwork name, and link contexts.
|
|
|
1746
|
b. UNI Transport Resource Addresses [term from
G.8080]. These addresses are use to
identify transport resources at a UNI reference point if they exist (SNPP
links do not have to be present at reference points). From the point of view of Call and
Connection Controllers in Access Group Containers, these are names. Control plane components and management
plane applications use these addresses.
|
|
|
1747
|
2. Control plane addresses for components. As per G.8080, the control plane consists
of a number of components such as connection management and routing. Components may be instantiated differently
from each other for a given ASON network.
For example, one can have centralized routing with distributed
signalling. Separate addresses are
thus needed for:
|
|
|
1748
|
a. Routing Controllers (RCs)
|
|
|
1749
|
b. Network Call Controllers (NCCs)
|
|
|
1750
|
c. Connection Controllers (CCs)
|
|
|
1751
|
Additionally, components have Protocol
Controllers (PCs) that are used for protocol specific communication. These also have addresses that are
separate from the (abstract) components like RCs.
|
|
|
1752
|
3. DCN addresses.
To enable control plane components to communicate with each other, the
DCN is used. DCN addresses are thus
needed by the Protocol Controllers that instantiate control plane
communication functions (generating and processing messages in protocol
specific formats).
|
|
|
1753
|
4. Management Plane Addresses. These addresses are used to identify
management entities that are located in EMS, NMS, and OSS systems.
|
|
|
1754
|
7.2 Routing Component Addresses
|
|
|
1755
|
For the ASON routing function, there are:
|
|
|
1756
|
- Identifiers for the RC itself. These are from the control plane address
space.
|
|
|
1757
|
- Identifiers for the RC Protocol Controller. These are from the control plane address
space.
|
|
|
1758
|
- Identifiers for communicating with RC PCs. These are from the DCN address space.
|
|
|
1759
|
- Identifiers for transport resources that the RC
is represents. These are from the
SNPP name space.
|
|
|
1760
|
- Identifier for a management application to
configure and monitor the routing function.
This is from the control plane address space.
|
|
|
1761
|
It is important to distinguish between the
address spaces used for identifiers so that functional separation can be
maintained. For example, it should be
possible to change the addresses used for communication between RC PCs (from
the DCN address space) without affecting the contents of the routing
database.
|
|
|
1762
|
This separation of name spaces does not mean that
identical formats cannot be used. For
example, an IPv4 address format could be used for multiple name spaces. However, they have different semantics
depending on the name space they are used in. This means that an identical value can be used for identifiers
that have the same format but are in different name spaces.
|
|
|
1763
|
7.3 Name Space Interaction
|
|
|
1764
|
The SNPP name space is one space that is used by
routing, signalling, and management functions. In order for the path computation function of an RC to provide
a path to a connection controller (CC) that is meaningful, they must use the
same SNPP name space. For
interactions between these routing and signalling, common encodings of the
name spaces are needed. For example,
the path computation function should return a path that CCs can
understand. Because SNPP name
constituents can vary, any RC and CC co-ordination requires common
constituents and semantics. For
example link contexts should be the same.
If an RC returns say a card context for links, then the CC needs to be
able to understand it. Similarly,
crankback/feedback information given to RCs from a CC should be encoded in a
form that the RC PC can understand.
|
|
|
1765
|
The SNPP name that an NCC resolves a UNI
Transport Address to must be in the same SNPP name space that both RC and CC
understand. This resolution function
resides in the control plane and other control plane identifiers may be
associated with this function.
|
|
|
1766
|
7.4 Name Spaces and Routing Hierarchy
|
|
|
1767
|
G.8080 does not restrict how many SNPs can be
used for a CP. This means that there
can be multiple SNPP name spaces for the same subnetwork. An important design consideration in routing
hierarchy can be posed as a question of whether one or multiple SNPP name
spaces are used. The following
options exist:
|
|
|
1768
|
1. Use a separate SNPP name space per level in a
routing hierarchy. This requires a
mapping to be maintained between each level.
However, level insertion is much easier with this approach.
|
|
|
1769
|
2. Use a common SNPP name space for all levels in a
routing hierarchy. A hierarchical
naming format could be used (e.g., PNNI addressing) which enables a
subnetwork name at a given level to be easily related to SNPP names used
within that subnetwork at the level below.
If a hierarchical name is not used, a mapping is required between
names used a different levels.
|
|
|
1770
|
7.5 SNPP
name components
|
|
|
1771
|
SNPP names consist of RAs, an optional subnetwork
id, and link contexts. The RA name
space is used by routing to represent the scope of an RC. This recommendation considers only the use
of fixed length RA identifiers. The
format can be drawn from any address-space global in scope. This includes IPv4, IPv6, and NSAP
addresses.
|
|
|
1772
|
The subnetwork id and link contexts are shared by
routing and signalling functions.
They need to have common semantics.
|
|
|
1773
|
8 Routing
and Call Control within a Hierarchy
|
|
|
1774
|
In this section we look at the flow of routing
information up and down the hierarchy, and the relationship between routing
and call control at various levels within a hierarchy.
|
|
|
1775
|
8.2 Routing
Information Flow
|
|
|
1776
|
At level N in a routing hierarchy under a link
state paradigm we are primarily interested in the links (data plane) between
the RCDs represented by the cooperating RCs at level N. Note however that in general the “node”
properties of an RC are derived from the corresponding level N-1 (next lower
level) RA. Note that links (data plane) between level N-1 RA are actually
level N RA links (or higher) as shown in Error! Reference source not found.. In addition, in some cases it may be very
useful for an RC to offer some approximate representation of the internal
topology of its corresponding RCD. It
is important to assume that the next lower level RA may implement a different
routing protocol than the link state protocol described in this
recommendation. Information from lower
levels is still needed. Such information flow is shown in Error! Reference source not found. between, e.g., levels N-1, RC 11, of RA 505 and
level N, RC 12 of RA 1313.
|
|
|
1777
|
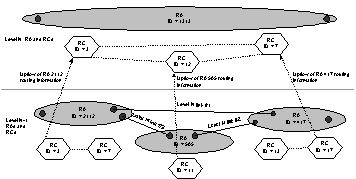
Figure 2. Example hierarchy with up flow of information
from RCs
|
|
|
1778
|
1) Although summarization of information could be
done across this interface, the lower level RC is not in a good position to
understand the scope of the higher level RA and its desires with respect to
summarization, hence initially this interface will convey similar link state
information as a peer (same level) RC interface. This leaves the summarization functionality to the higher level
RC. Hence we have a control adjacency
(but no data plane adjacency between these RCs). Also their relationship is of a hierarchical nature rather than
peer.
|
|
|
1779
|
For 2)/3) above: The physical locations of the
two RC, their relationship, and their communication protocol are not
currently standardized; however they are considered two separate RC,
belonging to two separate RAs. It should be noted that no data plane or
control plane adjacency exists between them.
|
|
|
1780
|
Information is exchanged by an RC with (a) other
RCs within its own routing area; (b) parent RCs in the routing area
immediately higher; and (c) child RCs in any routing areas immediately below
(i.e., supporting subnetworks within its routing area).
|
|
|
1781
|
It is assumed that the RC uses a link-state
routing protocol within its own routing area, so that it exchanges
reachability and topology information with other RCs within the area.
|
|
|
1782
|
However, information that is passed between
levels may go through a transformation prior to being passed
|
|
|
1783
|
-- transformation may involve operations such as
filtering, modification (change of value) and summarization (abstraction,
aggregation)
|
|
|
1784
|
This specification defines information elements
for Level N to Level N+1/N-1 information exchange
|
|
|
1785
|
Possible styles of interaction with parent and
child RCs include: (a) request/response and (b) flooding, i.e., flow up and
flow down.
|
|
|
1786
|
[Editor's note: more text may be needed on
request/response]
|
|
|
1787
|
8.2 Routing
Information Flow Up and Down the Hierarchy
|
|
|
1788
|
Information that flows up and down between the RC
and its parent and child RCs may include reachability and node and link
topology
|
|
|
1789
|
-- multiple producer RCs within a routing area
may be transforming and then passing information to receiving RCs at a
different level; however in this case
the resulting information at the receiving level must be self-consistent,
i.e., coordination must be done among the producer RCs
|
|
|
1790
|
-- the goal is that information elements should
be capable of supporting interworking of different routing paradigms at the
different levels, e.g., centralized at one level and link state at
another. We will focus on a subset of
cases: passing of reachability
information; passing of topology information. A minimum amount of information might be the address of an RC
in an adjacent level that can help to resolve an address.
|
|
|
1791
|
8.2.1 Requirements
|
|
|
1792
|
In order to implement multi-level hierarchical
routing, two issues must be resolved:
|
|
|
1793
|
- How do routing functions within a level
communicate and what information should be exchanged?
|
|
|
1794
|
- How do routing functions at different levels
communicate and what information should be exchanged?
|
|
|
1795
|
In the process of answering these questions, the
following model will be used:
|
|
|
1796
|
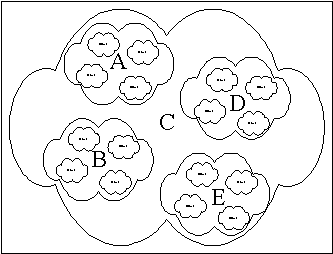
Figure 3.: Area Containment Hierarchy
|
|
|
1797
|
For this model, Levels are relative, and numbered
from bottom up. So, Area A and Area B
are at Level n while Area C is at Level n+1.
|
|
|
1798
|
The numbers shown in the model represent
different Intermediate Systems located within the various areas, and will be
referenced in the following sections.
|
|
|
1799
|
8.2.2 Communication
between levels
|
|
|
1800
|
8.2.2.1 Type
of information exchanged
|
|
|
1801
|
The communication between levels describes the
interface between a routing function in an aggregation area, and the routing
function(s) operating in a contained area.
|
|
|
1802
|
The following potential cases are identified:
|
|
|
1803
|
|
|
Parent RA info received
|
|
|
|
Case
|
Reachability
|
Topology
|
Comments
|
|
1
|
Full
|
Full
|
Example: different routing
protocols used in different areas at the same level, routing information
must be exchanged through a mutual parent area or areas
Note: local path computation has flexibility as
to the detail of the route specified beyond the local area
|
|
2
|
Full
|
Partial
|
abstracted topology is
received for some area(s)
Note: local path computation cannot result in
the full path and further route
resolution will occur at a later point
|
|
3
|
Full
|
Minimal or None
|
Minimal topology
information may support the
selection of a particular egress point.
If no topology information is available then all egress points are
considered equivalent for routing.
|
|
4
|
Partial
|
Partial
|
Reachability information
provided in the form of summarized addresses
Local path computation must be done assuming
that the address is resolvable
It is also possible that reachability is not
provided for a particular address
In this case no path can be computed
Same comments as above on topology
|
|
5
|
Partial
|
Minimal or None
|
Similar comments
|
|
6
|
Minimal
|
None
|
Path computation server
approach.
|
|
|
Child RA info received
|
|
|
|
|
Reachability
|
Topology
|
Comments
|
|
7
|
Full
|
Full
|
|
|
8
|
|
Partial
|
|
|
9
|
|
None
|
|
|
10
|
Partial
|
Partial
|
|
|
11
|
|
None
|
|
|
12
|
None
|
None
|
|
Note: not all cases are considered useful or will
be addressed
|
|
|
1804
|
The information flowing upward (i.e. Level n to
Level n+1) and the information flowing downward (i.e. Level n+1 to Level n)
are used for similar purposes -- namely, the exchange of reachability
information and summarized topology for endpoints outside of an area. However, different methods may be
used. The next two sections describe
this further.
|
|
|
1805
|
[More detailed text is needed in this section
regarding what summarized topology information needs to be fed up/down the
hierarchy. This needs to be
considered in conjunction with the configuration procedure and routing
attributes described later in this document.]
|
|
|
1806
|
8.2.2.2 Upward
communication from Level n to Level n+1
|
|
|
1807
|
[Editor's note: text needs to be updated to
include exchange of topology information and full/partial/minimal cases
described in the table above]
|
|
|
1808
|
Two different approaches exist for upward
communications. In the first approach
the Level n+1 routing function is statically configured with the endpoints
located in Level n. This information
may be represented by an address prefix to facilitate scalability, or it may
be an actual list of the endpoints in the area.
|
|
|
1809
|
In the second approach, the Level n+1 routing
function listens to the routing protocol exchange occurring in each contained
Level n area and retrieves the endpoints being announced by the Level n
routing instance(s). This information
may be summarized into one or more prefixes to facilitate scalability.
|
|
|
1810
|
Some implementations have extended the weakly
associated address approach. Instead
of using a static table of prefixes, they listen to the endpoint
announcements in the Level n area and dynamically export the endpoints
reachable (either individually or as part of a prefix summary) into the Level
n+1 area.
|
|
|
1811
|
Some of the benefits that result from this
dynamic approach are:
|
|
|
1812
|
It allows address formats to be independent of
the area ID semantics used by the routing protocol. This allows a Service Provider to choose one of the common
addressing schemes in use today (IPv4, IPv6, NSAP address, etc.), and allows
new address formats to be easily introduced in the future.
|
|
|
1813
|
It allows for an endpoint to be attached to
multiple switches located in different areas in the service provider's
network and use the same address.
|
|
|
1814
|
For Multi-level, the lower area routing function
needs to provide the upper level routing function with information on the
endpoints contained within the lower area.
Any of these approaches may be used.
However, a dynamic approach is preferable for the reasons mentioned
above.
|
|
|
1815
|
8.2.2.3 Downward
communication from Level n+1 to Level n
|
|
|
1816
|
[Editor's note: text needs to be updated to
include exchange of topology information and full/partial/minimal cases
described above]
|
|
|
1817
|
Four different approaches exist for downward
communications. In the first
approach, switches in an area at Level n that are attached to Level n+1 will
announce that they are a border switch, and know how to get to endpoints
outside of the area. When another
switch within the area is presented with the need to develop a route to
endpoints outside of the area, it can simply find a route to the closest
border switch.
|
|
|
1818
|
The second approach has the Level n+1 routing
function determine the endpoints reachable from the different Level n border
switches, and provide that information to the Level n routing function so it
can be advertised into the Level n area.
These advertisements are then used by non-border switches at Level n
to determine which border switch would be preferable for reaching a
destination.
|
|
|
1819
|
When compared to the first approach the second
approach increases the amount of information that needs to be shared within
the Level n area. However, being able
to determine which border switch is closer to the destination causes the
route thus generated to be of "higher quality".
|
|
|
1820
|
The third approach has the Level n+1 routing
function provide the Level n routing function with all reachability and
topology information visible at Level n+1.
Since the information visible at Level n+1 includes the information
visible at Levels n+2, n+3, and so on to the root of the hierarchy tree, the
amount of information introduced into Level n is significant.
|
|
|
1821
|
However, as with the second approach, this
further increases the quality of the route generated. Unfortunately, the lower levels will never
have the need for most of the information propagated. This approach has the highest
"overhead cost".
|
|
|
1822
|
A forth approach is to not communicate downward
from Level n+1 to Level n any routing information. Instead, the border switches provides other switches in the
area with the address of a Path Computation Server (PCS) that can develop
routes at Level n+1. When a switch
operating in an area at Level n needs to develop a route to a destination
located outside that area, the PCS at Level n+1 is consulted. The PCS can then determine the route to
the destination at Level n+1. If this
PCS also is unable to determine the route as the endpoint is located outside
of the PCS's area, then it can consult the PCS operating at Level n+2. This recursion will continue until the PCS
responsible for area at the lowest level that contains both the source and
destination endpoints is reached.
|
|
|
1823
|
For Multi-level, any of these approaches may be
used. The second and forth approaches
are preferable as they provide high-quality routes with the least amount of
overhead.
|
|
|
1824
|
8.2.2.4 Interactions
between upward and downward communication
|
|
|
1825
|
Almost all combinations of upward (Level n to
Level n+1) and downward (Level n+1 to Level n) communications approaches
described in this document will work without any problems. However, when both the upward and downward
communication interfaces contain endpoint reachability information, a
feedback loop is created.
Consequently, this combination must include a method to prevent
re-introduction of information propagated into the Level n area from the
Level n+1 area back into the Level n+1 area, and vice versa.
|
|
|
1826
|
Two methods that may be used to deal with this
problem are as follows. The first
method requires a static list of endpoint addresses or endpoint summaries to
be defined in all machines participating in Level n to Level n+1
communications. This list is then
used to validate if that piece of endpoint reachability information should be
propagated into the Level n+1 area.
|
|
|
1827
|
The second approach attaches an attribute to the
information propagated from the Level n+1 area to the Level n area. Since endpoint information that was
originated by the Level n area (or a contained area) will not have this
attribute, the routing function can break the feedback loop by only
propagating upward information where this attribute is appropriately set.
|
|
|
1828
|
For the second approach, it is necessary to make
certain that the area at Level n does not utilize the information received
from Level n+1 when the endpoint is actually located within the Level n area
or any area contained by Level n.
This can be accomplished by establishing the following preference
order for endpoints based on how an endpoint is reached. Specifically, the following preference
order would be used:
|
|
|
1829
|
1) Endpoint is reached through a node at Level n
or below
|
|
|
1830
|
2) Endpoint is reached through a node above Level
n
|
|
|
1831
|
The second approach is preferred as it allows for
dynamic introduction of new prefixes into an area.
|
|
|
1832
|
8.2.2.5 Method
of communication
|
|
|
1833
|
Two approaches exist for handling Level n to
Level n+1 communications. The first
approach places an instance of a Level n routing function and an instance of
a Level n+1 routing function in the same system. The communications interface is now under control of a single
vendor, meaning its implementation does not need to be an open protocol. However, there are downsides to this
approach. Since both routing
functions are competing for the same system resources (memory, and CPU), it
is possible for one routing function to be starved, causing it to not perform
effectively. Therefore, each system
will need to be analyzed to identify the load it can support without
affecting operations of the routing protocol.
|
|
|
1834
|
The second approach places the Level n routing
function on a separate system from the Level n+1 routing function. For this approach, two different methods
exist to determine that a Level n to Level n+1 adjacency exists: static
configuration, and automatic discovery.
Static configuration relies on the network administrator configuring
the two systems with their peer, and their specific role as parent (i.e.
Level n+1 routing function) or child (i.e. Level n routing function).
|
|
|
1835
|
For automatic discovery, the system will need to
be configured with the RA ID(s) for its area, as well as the RA ID(s) of the
"containing" area. The RA
IDs will then be conveyed by the system in its neighbor discovery (i.e.
Hello) messages. This in turn allows
the system in the parent RA to identify its neighbor as a system
participating in child RA, and vise versa.
|
|
|
1836
|
8.3 LRM
to RC Communications
|
|
|
1837
|
8.3.1 General
Capabilities
|
|
|
1838
|
One of the responsibilities of the LRM is to
provide the RC with information
regarding the type and availability of resources on a link, and any changes
to those resources.
|
|
|
1839
|
This requires the following basic functions
between the LRM and the RC:
|
|
|
1840
|
1) RC query to LRM of current link capabilities and
available resources
|
|
|
1841
|
2) LRM notification to RC when a signification
change occurs
|
|
|
1842
|
3) LRM procedure to determine when a change is
considered significant
|
|
|
1843
|
4) LRM procedure to limit notification frequency
|
|
|
1844
|
The initialization process for the RC must first
query the LRM to determine what resources are available and to populate its
topology database with information is it responsible for sourcing into the
network. The RC is then responsible for advertising this information to
adjacent RCs and ensuring that other RCs can distinguish between current and
stale information.
|
|
|
1845
|
After the initialization process, the LRM is
responsible for notifying the RC when any changes occur to the information it
provided. The LRM must implement procedures that prevent overloading the RC
with rapid changes.
|
|
|
1846
|
The first procedure that must be performed is the
determination of when a change is significant enough to notify the RC. This
procedure will be dependent on the type of transport technology. For example,
the allocation of a single VC11 or VC12 may not be deemed significant, but
the allocation of a single wavelength on a DWDM system may be significant.
|
|
|
1847
|
The second procedure that must be performed is a
pacing of the messages sent to the RC. The rate at which the RC is notified
of a change to a specific parameter must be limited (e.g. once per second).
|
|
|
1848
|
8.3.2 Physical
Separation of LRM and RC
|
|
|
1849
|
The physical separation of the LRM and the RC is
a new capability not previously supported in any protocol.
|
|
|
1850
|
The required interaction is similar to the
distribution of topology information between adjacent RCs, except that the
flow of information is unidirectional from the LRM to the RC.
|
|
|
1851
|
This interaction can be performed using a
modified lightweight version of an existing routing protocol. The initial
query from the RC to the LRM can reuse the database summary and LSA request
used during synchronization of the link-state database. Updates from the LRM
to the RC can use normal link-state database update messages.
|
|
|
1852
|
The LRM would not need to implement any
procedures for the reception of link-state information, flooding, topology
database, etc.
|
|
|
1853
|
8.4 Configuring
the hierarchy and information flow
|
|
|
1854
|
[Editor's note: text in this section needs to be
made protocol-independent]
|
|
|
1855
|
[Ed. The following text is still in draft form
and to be discussed further]
|
|
|
1856
|
1. I think we all agree we don’t want to use the level
indicator as in the PNNI when working on the protocol. The benefits to not
have it including the flexibility in inserting a level in between two
existing one, grouping two existing RA/RC into one RA, etc., without worrying
about the level violation and complexity. We can still use “level” literally,
but with relativity only and without code point defined.
|
|
|
1857
|
2. [Ed. Keep this paragraph as a comment for now but
it won’t make it to the final version] All nodes assigned the same RA ID will
be in the same RA running the link-state protocol. We need to say how the
control channels being defined and verified via their communications, or
completely auto-discovered. This is required at each hierarchy.
|
|
|
1858
|
3. [Ed. the way we instantiate the function that provides
the interaction with the higher level needs to be decided] With a RA, there
requires one or more RC that functions as “Peer Group Leader” to perform
additional duties, including summarizing addresses, aggregating data plane
topology etc. within its RA. The information is then communicated to one or
more RC at the next higher-level RA. The summarization and aggregation can
automatically occur but can also be accomplished via configuration. But the
“relationship” between the RC at the level N and the RC at the level N+1
needs to be described. Note in PNNI, the two RCs are generally realized by
two logical RC on the same switch with the internal IPC as their
communication channel; shall we either assume this, leave this as blank (as
in PNNI spec), or something else?
|
|
|
1859
|
4. There may be traffic types as the following that
need to be distinguished on the packet-based control channels: [Ed. need to
work on this part]
|
|
|
1860
|
a) Packets between peer-RC in
the same RA. These packets should carry the same RA ID.
|
|
|
1861
|
b) Packets received by the same
switch but may be for different RC on that switch, and they should carry
different RA ID or/and different RC ID. Note these packets may have different
destination IPv4/IPv6/NSAP address, but this could be optional, to save address space – RA ID or RC ID cost
nothing.
|
|
|
1862
|
5. Information feed-up:
|
|
|
1863
|
a) For reachable address, the information is always
feed-up one level at a time as is, without other additional information
attached. This feed-up occurs recursively level-by-level upwards, with
possible further summarization at any level.
|
|
|
1864
|
b) For aggregated data plane topology (such as
border-border TE links), it is always feed-up one level at a time as is,
without other additional information attached.
|
|
|
1865
|
Some of the TE links feed-up may need to include
the “ancestor RC ID”, so it feed-up upwards until the ancestor RC gets it.
|
|
|
1866
|
The RC at the level N+1 should have enough
information not to feed-down the information.
|
|
|
1867
|
6) Information feed-down:
|
|
|
1868
|
The RC at the level N+1 should filter out the
routing information feed-up from down stairs during the feed-down operation,
and that is, the RC at the level N+1 only feed-down information it learnt
from other RC in the same RA (at the level N+1), which will be the
information to the RC at the level N as from other RA.
|
|
|
1869
|
9 Control
Adjacencies
|
|
|
1870
|
9.1
Within an RA
[Editor's note: e.g., between RCs across a lower
level area boundary]
|
|
|
1871
|
9.2
Between Levels
[Editor's note: between parent and child RCs when
in different systems]
|
|
|
1872
|
10. Discovery
and Hierarchy
|
|
|
1873
|
Given data plane connectivity between two
different RCDs that we wish to have cooperate within a RA we have two
choices: (a) configure the corresponding RCs with information concerning
their peers, or (b) discover the suitable corresponding RC on the basis of
information shared via some type of enhanced NNI discovery procedure.
|
|
|
1874
|
One fairly straight forward approach is for each
side to share information concerning its RA containment hierarchy along with
the addresses of the appropriate protocol controller for the RC within each
of these RAs.
|
|
|
1875
|
11 Routing
Attributes
|
|
|
1876
|
11.1. Principles
[Editor's note: sections 11.1 thru 11.5 taken
from wd21 sections 1-5]
|
|
|
1877
|
The architecture of Optical Networks is
structured in layers to reflect technology differences and or switching
granularity. This architecture follows a recursive model as described in
Recommendation G.805. The Control plane is consistent with this model and
thus enables Optical Networks to meet client signal requirements such as
service type (VC-3 for VPNs), a specific quality of service, and the specific
layer adaptations. Thus an ASON link
is defined to be capable of carrying only a single layer of switched traffic. The fact that an ASON link is a single
layer allows layers to be treated in the same way from the point of view of
Signalling, Routing and Discovery. This requires that layers are treated
separately and there is a layer-specific instance of the signalling, routing
and discovery protocols running. From the routing point of view, it means
that path computation needs to be able to find a layer specific path.
|
|
|
1878
|
The hierarchical model of routing in G.7715 leads
to several instances of the Routing protocol (e.g., instantiation of several
hierarchies) operating over a single layer. Therefore, a topology may be
structured with several routing levels of the hierarchy within a layer before
the layer general topology is distributed. Hence a model is needed to enable
effective routing on a layered transport network.
|
|
|
1879
|
Additionally, transport layer adaptations are
structured within an adaptation hierarchy which requires explicit indication
of layer relationships for routing purposes. This is illustrated in Figure 1.
|
|
|
1880
|
Fig 1.Layer structure in SDH
|
|
|
1881
|
In transport networks, a Server layer trial may
support different adaptations at the same time, which creates dependency
between the layers. This makes necessary that the variable adaptation
information needs to be distinguishable at each layer (e.g., VC-3 supporting
n-VC-12c and m-VC-11c). A specific example is a server layer trail VC-3
supporting VC-11 and VC-12 client layers. In this case, a specific attribute
like bandwidth can be supported in different ways over the same common server
layer through the use concatenation.
If VC-11c is chosen to support the VC-3, the availability of the VC-12
is affected, information that needs to be known by routing. Each of these two client layers have also
specific constraints (e.g., cost), that routing need to understand on a layer
basis.
|
|
|
1882
|
Furthermore, routing for transport networks is
done today by layer, where each layer may use a particular routing paradigm
(one for DWDM layer and a different one for VC layer) This layer separation requires that
attributes information be also separately handled by layer.
|
|
|
1883
|
In Heterogeneous networks some NEs do not support
the same set of layers (case that also applies to GMPLS). Even if this NE
does not support a specific layer, it should be able to know if other NE in
the network supports an adaptation that would enable that unsupported layer
to be used.
|
|
|
1884
|
[Editor's note: example needed]
|
|
|
1885
|
Separate advertisement of the layer attributes
may be chosen but this may lead to unnecessary duplication since some
attributes can be derived from client-server relationships. These are
inheritable attributes, property that can be used to avoid unnecessary
duplication of information advertisement. To be able to determine inherited
attributes, the relationship between layers need to be advertised. Protection and Diversity are examples of
inherited attributes across different layers. Both Inherited and Layer
specific attributes need to be supported.
|
|
|
1886
|
The interlayer information advertisement is
achieved through the coordination of the LRMs responsible for SNPPs at each
layer. Some of the attributes to be exchanged between layers reside on the
Discovery Agent where they have been provisioned or determined through the
layer adjacency discovery process. To
get this information, the LRMs access DA information through the TAP, as
allowed by G.8080 components relationships.
|
|
|
1887
|
In view of the fact that not all NEs support all
layers today but may do so in the future, representation of attributes for
routing needs to allow for new layers to be accommodated between existing
layers. (This is much like the notion of the generalized label).
|
|
|
1888
|
As per G.805, a network a specific layer can be
partitioned to reflect the internal structure of that layer network or the
way that it will be managed. It’s
also possible that a subset of attributes is commonly supported by subsets of
SNPP links located in different links (G.7715 subpartition of SNPPs). This means
that it should be possible to organize link layers based on attributes and
that routing needs to be able to differentiate attributes at specific layers.
For example, an attribute may apply to a single link at a layer, or it may
apply to a set of links at the same layer.
|
|
|
1889
|
11.2. Taxonomy of Attributes
|
|
|
1890
|
Following the above architectural principles,
attributes can be organized according to the following categories:
|
|
|
1891
|
Attributes related to a node or to a link
|
|
|
1892
|
Provisioned or negotiated. Some attributes like
Ownership and Protection are provisioned by the customer while adaptation can
be configured as part of an automatic discovery process.
|
|
|
1893
|
Inherited and layer specific attributes. Client
layers can inherit some attributes from the Server layer while others
attributes like Link Capacity are specified by layer.
|
|
|
1894
|
Attributes used by a specific Plane or Function:
Some attributes are relevant only to the transport topology while others are
relevant to the control plane and furthermore, they are specific to a control
plane function like Signalling, Routing or Discovery (e.g. Cost for routing).
The Transport Discovery Process can be used to exchange control plane related
attributes that are unrelated to transport plane attributes. The way that the
exchange is done is out of the scope of this recommendation.
|
|
|
1895
|
While a set of attributes can apply to both
planes, others have meaning only when a Control plane exists. E.g., SRLG and delay for the SNPPs
|
|
|
1896
|
11.3. Relationship
of links to SNPPs
|
|
|
1897
|
SNPP links as per G.8080 are configured by
operator through grouping of SNPs
links between the same two routing areas within the same layer. These two
routing areas may be linked by one or more SNPP links. Multiple SNPP links
may be required when SNP links are not equivalent for routing purposes with
respect to routing areas they are attached, or to the containing routing
area, or when smaller groupings are required for administrative purposes.
Routing criteria for grouping of SNPP links can be based on different
criteria (e.g., diversity, protection, cost, etc).
|
|
|
1898
|
11.4. Attributes
and the Discovery process
|
|
|
1899
|
Some attributes are used for generic purposes of
building topology. These basic attributes are exchanged as part of the
transport discovery process. Part of this attributes are inherent to the
transport discovery process (Adaptation potential) and others are inferred
from high level applications (e.g., Diversity, Protection).
|
|
|
1900
|
Attributes used only by the control plane can be
provisioned/determined as part the Control Plane Discovery process.
|
|
|
1901
|
11.5. Configuration
|
|
|
1902
|
Several possible configurations can be done to
organize the SNPPs required for Control plane. Configuration includes:
|
|
|
1903
|
Provisioning of link attributes
|
|
|
1904
|
Provision of SNPPs is based on the attributes of
the different SNPPs components (i.e. routing, cost, etc.).
|
|
|
1905
|
Provisioning of specific attributes that are
relevant only to SNPPs
|
|
|
1906
|
Configuration can be done at each layer of the
network but this may lead to unnecessary repetition. Inheritance property of
attributes can also be used to optimize the configuration process.
|
|
|
1907
|
11.6 Attributes in the Context of Inter RCD and
Intra RCD Topology
|
|
|
1908
|
[Editor's note: moved from original wd31/G.7715.1
section 11.1]
|
|
|
1909
|
For practical purposes we further differentiate
between two types of topology information. Topology between RCDs and topology
internal to a RCD. Recall that the
internal structure of a control domain is not required to be revealed.
However, since an entire RA is represented as a RCD (with a corresponding RC)
at the next level up in the hierarchy there are a number of reasons (some of
which are detailed below) to reveal additional information. At a given level of hierarchy we may
choose to represent a given RCD by a single node or we may represent it (or
part of it) as a graph consisting of nodes and links. This is the process of topology/resource
summarization and how this process is accomplished is not subject to
standardization.
|
|
|
1910
|
11.7 Node and Link Attributes
|
|
|
1911
|
Per the approach of G.7715 we categorize our
routing attributes into those pertaining to nodes and those pertaining to links.
When we speak of nodes and links in this manner we are treating them as
topological entities, i.e., in a graph theoretic manner.
|
|
|
1912
|
Other information that could be advertised about
an RA to the next level up could be aggregate characteristic properties. For example, the probabilities of setting
up a connection between all pairs of gateways to the RA. SRG information about the RA could also be
sent but without detailed topology information. [ Editor's note: placement of
this paragraph tbd]
|
|
|
1913
|
11.8 Node
Attributes
|
|
|
1914
|
[Ed. Note: from original wd31/G.7715.1 section
11.4]
|
|
|
1915
|
All nodes represented in the graph representation
of the network belong to a RA, hence the RA ID can be considered an attribute
of all nodes.
|
|
|
1916
|
11.8.1 Nodes
Representing RCDs [Editor's note: need to fix title and terminology]
|
|
|
1917
|
When a node is representing an entire RCD then it
is can be considered equivalent to the RC.
|
|
|
1918
|
For such a node we have the following attributes
|
|
|
1919
|
- RC ID (mandatory) – This number must be unique
within an RA.
|
|
|
1920
|
- Address of RC (mandatory) – This is the SCN
address of the RC where routing protocol messages get sent.
|
|
|
1921
|
- Subnetwork ID
|
|
|
1922
|
- Client Reachability Information (mandatory)
|
|
|
1923
|
- Hierarchy relationships
|
|
|
1924
|
- Node SRG (optional) – The shared risk group
information for the node.
|
|
|
1925
|
- Recovery (Protection/Restoration) Support – Does
the domain offer any protection or restoration services? Do we want to advertise them here? Could be useful in coordinating restoration…?
|
|
|
1926
|
- General Characteristics: Transit Connections,
Switching and branching capability, RCD dedicated path protection (e.g., 1:1,
1+1). (mandatory) à [Ed: This is really to express the idea that you
really can’t get across this domain, either due to policy reasons or by
blocking properties. Needed?][Editor's Note: could be replaced by a link-end
transit attribute]
|
|
|
1927
|
11.8.2 Intra-RCD
Abstract Nodes [Editor's note: need to fix title and terminology]
|
|
|
1928
|
The nodes used to represent the internal RCD
topology can be advertised within the NNI routing protocol. These nodes may
correspond to physical nodes, such as border nodes or internal physical
nodes, or logical or abstract nodes. Each node advertised within the NNI
routing is identified by:
|
|
|
1929
|
- RC ID (mandatory) – Let’s us know which RCD to
which this intra-domain node belongs.
|
|
|
1930
|
- Intra-Domain Node ID (mandatory) – Used to
uniquely identify the intra domain abstract node within the RCD.
|
|
|
1931
|
- Client Reachability Information (optional) –
Usually would want this information for diverse source and destination
services.
|
|
|
1932
|
- Node SRG (optional) – The shared risk group
information for the node.
|
|
|
1933
|
11.8.3 Additional
Information on Node Attributes
|
|
|
1934
|
11.8.3.1 Intra-RCD
Node ID
|
|
|
1935
|
In the case of physical nodes, the node ID is
simply the node ID of the physical node itself. Otherwise the node is at some level of the routing hierarchy
and can be named with an RA id.
|
|
|
1936
|
It may be possible to extract the node
information from link state advertisements, thus it may not be necessary to
explicitly advertise this information.
|
|
|
1937
|
11.8.3.2 Protection and restoration support
|
|
|
1938
|
The type of restoration and protection mechanisms
supported within a control domain is represented by this attribute. N.B. This is a control domain attribute
and does not necessarily apply only to intra-RCD nodes. The protection and
restoration options specified include:
|
|
|
1939
|
[Ed. this
may be changed to a general field rather than being specific as it is right
now]
|
|
|
1940
|
- Link protection
|
|
|
1941
|
- RCD dedicated path protection (e.g., 1:1, 1+1)
|
|
|
1942
|
- Dynamic restoration (i.e., re-provisioning after
failure)
|
|
|
1943
|
- Shared mesh restoration
|
|
|
1944
|
Other carrier specific protection and restoration
schemes may also be supported.
|
|
|
1945
|
11.8.4 Client
Reachability
|
|
|
1946
|
Reachability information describes the set of end
systems that are directly connected to a given control domain. One technique
is to use a directory service to determine the control domain and/or the
specific node to which a given client is physically connected. The alternative is to advertise client
reachability through the NNI routing protocol. This is an optional capability of the routing protocol.
|
|
|
1947
|
There are multiple ways to advertise client
reachability information. Speaker nodes may advertise client reachability on
a per-domain basis if path within the client domain is not desired. Speaker nodes may alternatively advertise
client reachability in a more detailed fashion so that more optimized route
selection can be performed within a connection’s destination control
domain. Ideally, the network operator
has allocated end system addresses in a manner that can be summarized so that
only a small amount of reachability information needs to be advertised.
|
|
|
1948
|
11.8.4.1 Reachability
Information
|
|
|
1949
|
Client reachability is advertised as a set of
clients directly connected to each domain. In this case, the attributes
related to the reachability advertisement include:
|
|
|
1950
|
- RA ID, RC ID, and possibly inter-RCD node ID
|
|
|
1951
|
- List of UNI Transport Resource addresses or
address prefixes
|
|
|
1952
|
- List of SNPP Ids (Editor's note: can have
variable context depth as in G.8080 Amend. 1)
|
|
|
1953
|
Note that it is possible for client addresses to
be connected by more than one RC or internal node. In that case, multiple RC ID, RA ID, etc. should be associated
with those client addresses.
|
|
|
1954
|
UNI Transport Resource Addresses are assigned by
the service provider to one or more UNI transport links (see Recommendations
G.7713.x). The UNI Transport Resource Address may be an IPv4, IPv6 or an NSAP
address.
|
|
|
1955
|
11.9 Link Attributes
|
|
|
1956
|
[Editor's note: some further reorganization from
WD21 was done to improve flow]
|
|
|
1957
|
11.9.1
Inter-RCD links and Intra-RCD abstract links
|
|
|
1958
|
The links between RCDs are sometimes called external
links. The connectivity between and
within control domains is represented by intra-RCD and inter-RCD (external)
links.
|
|
|
1959
|
The advertisement of the external links is
crucial for supporting following service functionalities:
|
|
|
1960
|
1) Load balancing: by advertising external links to
other domains, it is possible to achieve load balancing among external links
between neighbor control domains via available load balancing scheme. Lack of
load balancing on external links may end up with uneven loads on intra-domain
nodes and links.
|
|
|
1961
|
2) Fast end-to-end dynamic restoration:
domain-by-domain restoration may be used for intra-domain link and node
failures, but cannot be used to recover from border node failures. Fast
end-to-end restoration can instead be used to recover from border node
failures. With knowledge of the external links, source nodes can identify
external links through alternate border nodes to achieve rapid restoration
with minimal crankback.
|
|
|
1962
|
3) End-to-end diverse routing: to achieve node and
SRLG diversity for connections across multiple domains, we require selection
of different border nodes / SRLG disjoint external links. This could be
achieved using crankback mechanisms to “search” for physically diverse
routes. However, advertising external links would significantly reduce the
crankback required, particularly if physically diverse paths are available within
control domains.
|
|
|
1963
|
Representation of links internal to a RCD that
are advertised outside the RCD are called intra-RCD abstract links. Intra-RCD
abstract links are important when efficient routing is required across /
within a RCD (e.g., in core / long distance networks). Efficient routing can
be achieved by advertising intra-RCD abstract links with metrics (costs)
assigned to them, so long as the metrics are common across all RCDs.
|
|
|
1964
|
The methods for summarizing control domain
topologies to form an abstract topology trade off network scalability and
routing efficiency. In addition, abstract topology allows treatment of
vendor/domain specific constraints (technological or others). These methods can be a carrier / vendor
specific function, allowing different carriers to make different
tradeoffs. Resulting abstract
topologies can vary from the full topology, a limited set of abstract links,
or hub-spoke topologies. Note in addition to the intra-RCD abstract links we
may use intra-RCD abstract nodes in the representation of a RCD’s internal
topology. These abstract nodes are
similar to the complex node representation described in section 3.3.8.2 of
PNNI spec. Abstract links are similar
to the exception bypass links of PNNI complex nodes. A metric of the intra-RCD abstract link
could be used to represent some potential capacity between the two border
nodes (on either end of the link) in that RCD.
|
|
|
1965
|
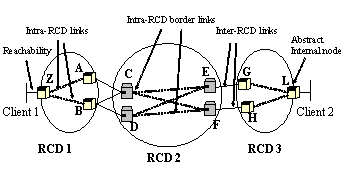
Figure 4. Topological elements relative to RCDs.
|
|
|
1966
|
Note that intra-RCD links advertised using the
NNI may be either physical or logical links, however, from the perspective of
the NNI speakers in other control domains, this distinction is not
relevant. This is because path
selection computes the end-to-end path based on the advertised links and
associated link state information, whether physical or logical. Although each
of these links has a different location with respect to control domains, the
attributes associated with them are essentially the same. We thus define the
same set of attributes for all types of RCD links.
|
|
|
1967
|
11.9.2 Inter-RCD
and Intra-RCD Link Attributes
|
|
|
1968
|
[Editor's
note: List below to be further refined and descriptions provided]
|
|
|
1969
|
[Editor's note: need to consider types of path
computation to be supported and use of configuration as an alternative means
to flooding to supply some information]
|
|
|
1970
|
The following Link Attributes are defined:
|
|
|
1971
|
- Connectivity Supported (e.g.
CTP, TTP, etc)
|
|
|
1972
|
- Bandwidth Encoding:
Describes how the capacity is supported and its availability. I.e. 48 MB
supported on a VC-3 circuit with the specific VC-3 structure (other
possibility is concatenation of Vc 12s). It can advertise potential numbers
of connections (192 STS-1 in an OC-192). (mandatory)
|
|
|
1973
|
- Adaptation
|
|
|
1974
|
- Client-Server Relationship
((Clients and server(s) of this layer, including signal and encoding type)
|
|
|
1975
|
- Attributes with
client-server relationships (e.g., SRLG, server adaptation)
|
|
|
1976
|
- Colour (e.g. for VPNs)
|
|
|
1977
|
- Metrics
|
|
|
1978
|
Link Inherited Attributes that can be determined
by client-server layer relationships:
|
|
|
1979
|
- SNPP name components (mandatory)
|
|
|
1980
|
- Subnetwork (matrix)
- Source
Subnetwork/NE ID
- Remote Subnetwork/NE ID
|
|
|
1981
|
- Link Context
e.g., "Bundle ID"
|
|
|
1982
|
Encoding (e.g., SONET/SDH, OTN)
|
|
|
1983
|
Recovery (Protection and restoration) support
|
|
|
1984
|
Link protection
|
|
|
1985
|
Dynamic restoration (i.e., re-provisioning after
failure)
|
|
|
1986
|
Shared mesh restoration
|
|
|
1987
|
Signalling (INNI, ENNI, UNI) [Editor's note: not
clear why this is needed]
|
|
|
1988
|
Ownership OSS, ASTN. It may be used as a criteria choice for CP points
that can be represented by SNPs
|
|
|
1989
|
Status: Blocked state could be temporary and
needs to be advertised [Editor's
note: seems to have some overlap with bandwidth encoding, needs to be
resolved]
|
|
|
1990
|
Lack of Diversity [Editor's note: needs further
explanation. One suggestion is that
an abstract link representing subnetwork connectivity between border points
might indicate a level of diversity, as an alternative to advertising all of
the SRLGs]
|
|
|
1991
|
11.9.2.1 Link
Source and Destination end Ids [Ed. note: SNPP Name?]
|
|
|
1992
|
For nodes representing RCD (i.e., RCs) the link
source/destination end ids consists of the RA ID and up to two 32 bit numbers
to uniquely identify the interface off the RCD. However, if desired for simplicity in setting unique values one
could use a triple such as (RA ID, Border Node IPv4 address, IfIndex). Note that the RA id sets the transport
context.
|
|
|
1993
|
For intra-RCD nodes the link source/destination
end ids consists of the triple (RA ID, Node ID, IfIndex), where the Node ID
was defined in the section on intra-RCD node attributes. One possible way to do this is by checking
if the RA Ids of the source and destination ends of the link are the same.
|
|
|
1994
|
11.9.2.2 Link
Capacity [Ed. note: Bandwidth Encoding and Adaptation?]
|
|
|
1995
|
Following the G.7715 model for routing, links are
layer specific and link properties are reported to the RC via the respective
LRM. Link capacity is characterized
in terms of a certain number of link
connections. Link connections
represent the indivisible unit of bandwidth for a link in a particular layer
network, e.g., a VC3 Link may contain ‘n’ VC3 link connections[2]. The RC uses the link information obtained
from the LRM in its route computation.
|
|
|
1996
|
Interesting cases of link bandwidth accounting
arise when equipment supporting flexible (or variable) adaptation are present
in the network. Flexible (or
variable) adaptation refers to the ability to tune adaptation functions in
the element to flexibly provide a variety of link connections from a common
trail. For example, an equipment
supporting a flexible adaptation of OC192 to 192 STS-1, 64 STS-3c, 16
STS-12c, 4 STS-48c or 1 STS-192c link connections. In this case, there are potentially different types of links
containing their respective types of link connections. However, given that all these link
connections are supported by a common trail, the allocation of resources
(link connections) from one link reflects as a “busy” state to a set of link
connections in other links. In the
above example, if one STS-3c is allocated, then the link states change as
follows: 189 STS-1, 63 STS-3c, 15 STS-12c, 3 STS-48c, 0 STS-192c. Note that flexible (or variable) adaptation
involves interactions between CTPs and TTPs and is as handled via
interactions between LRM and TAP.
Thus, the routing process does not concern itself with the “adaptation
mangement”, but only receives and uses information obtained from LRM.
|
|
|
1997
|
Thus far, we have considered the link state in
terms of “available capacity” vs. “used capacity” (or link connections in the
busy state). In addition to the
notion of “available capacity”, we introduce the notion of “potential
capacity” or “planned capacity”. This
refers to the amount of link capacity that is planned (via some form of
network engineering/planning). This
type of capacity considerations are useful in the context of long-term route
planning (or quasi-static route planning).
|
|
|
1998
|
11.9.2.3 Canonical
Representation of Link Capacity
|
|
|
1999
|
We have considered the interaction between LRM
and RC in terms of the link capacity attributes. We now consider the problem of how this information is
represented in the protocol LSA/LSPs in a canonical fashion. We observe that there are two possible
architectural models for canonical representations.
|
|
|
2000
|
The first model employs a protocol controller
which performs session multiplexing.
In this case, we have RCs which are layer specific that communicate
with each other through sessions that are multiplexed via the protocol
controller. The other model is to
have a information multiplexing in the protocol PDU. This is shown in Error! Reference source not found..
(a)
|
|
|
2001
|
(b)
|
|
|
2002
|
Figure 5 – (a) Protocol Controller employing session
multiplexing, (b) Protocol controller employing information element
multiplexing
|
|
|
2003
|
In Figure 6, depending on whether model (a) or
(b) is employed in the protocol design, two types of protocol encoding
choices arise.
|
|
|
2004
|
Regardless of the scenarios (a) and (b) for a
given link type, i.e., we would send the following information
|
|
|
2005
|
- Signal Type: This indicates the link type, for
example a VC3/STS1 path
|
|
|
2006
|
- Transit cost: This is a metric specific to this
signal type
|
|
|
2007
|
- Connection Types: Three choices transit, source or sink. This indicator allows the routing process
to identify whether the remote endpoint is flexibly or inflexibly connected
to a TTP or CTP. [Editor's note: does
this require a 'transit' attribute for link ends? if so, does this conflict
with the 'transit' attribute for nodes?]
|
|
|
2008
|
- Link capacity count fields:
|
|
|
2009
|
- Available count: The number of available,
non-failed link connections
|
|
|
2010
|
- Installed count:
The number of available + unavailable (i.e. failed) link connections
|
|
|
2011
|
- Planned count: The number of available +
unavailable + uninstalled link connections
|
|
|
2012
|
The amount of link connections in a specific
state is really more a function of the current "alarm" being seen –
if it’s a facility failure, then the link connection is included in the
installed count. If it’s an equipage
issue (i.e. card not installed) then the link connection would be included in
the planned count. Therefore, the
information does not necessarily need to be hand configured.
|
|
|
2013
|
11.9.2.4 Metric
|
|
|
2014
|
Each link is assigned a set of metrics. The
metrics used are service-provider specific, and are used in route selection
to select the preferred route among multiple choices. Examples of metrics include:
|
|
|
2015
|
1. A static administrative weight
|
|
|
2016
|
2. A dynamic attribute reflecting the available
bandwidth on the links along with the least cost route (e.g., increasing the
cost as bandwidth becomes scarce.) If
the metric is a dynamic attribute, nodes may limit the rate at which it is
advertised, e.g., using hysteresis.
|
|
|
2017
|
3. An additive metric that could be minimized (e.g.,
Db loss)
|
|
|
2018
|
4. A metric that a path computation may perform
Boolean AND operations on.
|
|
|
2019
|
11.9.2.5 Protection
|
|
|
2020
|
Several protection parameters are associated with
a link. They include:
|
|
|
2021
|
- A protection switch time. This indicates how long
the protection action will take. If
there is no protection, this value would represented by an infinity value.
|
|
|
2022
|
- An availability measure. This represents the
degree of resource reservation supporting the protection characteristic. For
example, a 1+1 linear protected link has 100% of reserved resources for its
protection action. A 1:n protected link has less than 100%.
|
|
|
2023
|
An intra-domain abstract link could be
representative of a connection within that domain. Protection characteristics of the connection would then be used
by that link. For example the connection could be protected with 1+1
trails (working and fully reserved protection trails). When a link can serve
higher layers (i.e., be multiply adapted), those higher layer links
"inherit" the protection characteristic of the (server) link.
|
|
|
2024
|
11.9.2.6 Shared
Risk Link Groups (SRLGs)
|
|
|
2025
|
A Shared Risk Link Group (SRLG) is an abstraction
defined by the network operator referring a group of links that may be
subject to a common failure. Each link may be in multiple SRLGs. The SRLGs
are used when calculating physically diverse paths through the network, such
as for restoration / protection, or for routing of diverse customer
connections. Note that globally consistent SRLG information is not always
available across multiple control domains, even within a single carrier.
|
|
|
2026
|
11.10. Intra-layer
and Interlayer Attributes Exchange
|
|
|
2027
|
[Editor's Note: Text from WD 21 section 10]
|
|
|
2028
|
Transport networks are built from bottom up,
starting by the lowest layer (Physical layer) supported by the network.
Following this architecture some attributes that are provisioned at the
lowest layers apply to upper layers or are inherited. The inherited
attributes can be inferred from client-server relationships and do not need
to be flooded between layers, allowing in this way to optimize the
information advertisement. Inherited attributes are tied to attributes with
common applicability to several layers.
|
|
|
2029
|
Other types of attributes are layer specific
attributes, which cannot be inferred from client-server relationships and
therefore need to be flooded between layers.
These attributes are determined through the Layer Adjacency Discovery
Process or provisioning. Then, they are passed between layers involving the
interaction of the Discovery Agent, TAPs and LRMS.
|
|
|
2030
|
Diversity is an attribute that can be inherited
and/or layer specific. It can be provisioned at the Physical layer or each
SNPP link. Lack of diversity could be inherited however the different diversity
values are layer specific and they need to distinguishable by layer. In all
cases it is necessary that attributes can be represented on a per layer
basis.
|
|
|
2031
|
11.11. Protocol-Independent
Description
|
|
|
2032
|
[Editor's Note: text from WD21 section 11]
|
|
|
2033
|
11.11.1 Generic PDU Information
|
|
|
2034
|
Based on the principles and taxonomy explained
above, the information advertised for routing in Optical networks has the
following format:
|
|
|
2035
|
11.11.1.1 Node
|
|
|
2036
|
<PDU Identifiers, <Layer Specific Node
PDU>* >
|
|
|
2037
|
[Editor's Note: further discussion needed on the
attributes below]
|
|
|
2038
|
<Layer Specific Node PDU> = <RC ID
address>
|
|
|
2039
|
<
RC PC Communication Address>
|
|
|
2040
|
<Subnetwork
ID>
|
|
|
2041
|
<Downwards
and Upwards Client Reachability>
|
|
|
2042
|
<Relationship
to attributes: Linkeages to other
Layers>.
|
|
|
2043
|
<Hierarchy
relationships >
|
|
|
2044
|
<Node
SRG>
|
|
|
2045
|
<Inheritable>*
|
|
|
2046
|
<Inheritable>* <Recovery Support>
|
|
|
2047
|
<Transit
Connection>
|
|
|
2048
|
<Others>
|
|
|
2049
|
11.11.1.2 Link
|
|
|
2050
|
<PDU Identifiers, <Layer Specific Link
PDU>* >
|
|
|
2051
|
[Editor's Note: Further discussion needed on the
attributes below]
|
|
|
2052
|
<Layer Specific Link PDU> = < Adaptation>
|
|
|
2053
|
<Connectivity Supported>
|
|
|
2054
|
<Bandwidth Encoding>
|
|
|
2055
|
<
Attributes with crosslayer relationships>
|
|
|
2056
|
<SRLGs>
|
|
|
2057
|
<Server
Adaptation>,
|
|
|
2058
|
<SNPP utilization> (1)
[Editor's note: to be further refined]
|
|
|
2059
|
<Colour>
|
|
|
2060
|
<Metrics>
|
|
|
2061
|
<Inheritable>*
|
|
|
2062
|
<Inheritable> = <Local
SNPP name>
|
|
|
2063
|
<Remote SNPP name>
|
|
|
2064
|
<Encoding Type>
|
|
|
2065
|
< Recovery Support>
|
|
|
2066
|
<Signalling>
|
|
|
2067
|
<Ownership>
|
|
|
2068
|
<Status>
|
|
|
2069
|
<Others>
|
|
|
2070
|
(1) SNPP utilization could be given in terms
of colour, or delay
|
|
|
2071
|
Appendix I
|
|
|
2072
|
Outline of Appendix text
(some points may need expansion)
|
|
|
2073
|
a. As specified in G.805, an
ASON layer network can be recursively partitioned into subnetworks. Subnetworks are management policy
artifacts and are not created from protocol actions or necessarily from
protocol concerns such as scalability.
Partitioning is related to policies associated with different parts of
a carrier network. Examples include
workforce organization, coexistence of legacy and newer equipment, etc. Subnetworks are defined to be completely
contained within higher level subnetworks.
|
|
|
2074
|
Figure A.I-1:
Distinction between Layering and partitioning
|
|
|
2075
|
b. Partitioning in the
transport plane leads to multiplicity of routing areas in the control
plane. Recursive partitioning using
the G.805 principles leads to hierarchical organization of routing areas into
multiple levels.
|
|
|
2076
|
|
|
|
|
Figure A.I-2:
Hierarchical Organization of Routing Areas
[Editor;s note: figure needs to be understandable
in black and white]
|
|
|
2077
|
c. Some relevant characteristics of ASON network
topologies: there is typically not a single backbone. Traffic cannot be forced go through a backbone, as this is
inconsistent with the topology, also regulatory concerns may add requirements
for local call routing policies.
|
|
|
2078
|
d. Routing areas follow the organization of
subnetworks. Routing area
organization must support ASON network topology, .e.g., there should not be a
requirement for a single backbone area, containment relationship must be
followed.
|
|
|
2079
|
Figure A.I-3 contains an example of a transport
network consisting of two carrier backbone networks. The metro transport networks connected to
the backbones have the choice of which backbone to use to reach other metro
networks. Also, adjacent metro
networks can support connections between them without those connections
traversing either backbone network.
|
|
|
2080
|
Figure A.I-3: Example
Network Topology
[Editor's note: add links between Metro 1 and
Carrier B, Metro 2 and Carrier A, etc.]
|
|
|
2081
|
e. The protocol should attempt to minimize the
amount of talking between RCs, e.g., by passing multiple level information
together. Typically, because of
scoping, only two or three levels might be passed - myself, my children, and
my parents…..? The further away the
destination, the more abstraction may be used to reduce the amount of
information that must be passed.
|
|
|
2082
|
f. The internal topology of a subnetwork is
completely opaque to the outside. For
routing purposes, the subnetwork may appear as a node (reachability only), or
may be transformed to appear as some set of nodes and links, in which case
the subnetwork is not visible as a distinct entity. Methods of transforming subnetwork structure to improve routing
performance will likely depend on subnetwork topology and may evolve over
time.
|
|
|
2083
|
Appendix I original from Eve
Outline of Appendix text (some points may need
expansion in main body)
|
|
|
2084
|
a. Partitioning in the transport plane leads to
hierarchy in the control plane.
|
|
|
2085
|
b. Subnetworks are management policy artifacts –
they don’t come from protocol organization.
|
|
|
2086
|
c. Partitions are not chosen because of autonomous
protocol actions. These relate to
policies at different parts of the network.
Access is not usually used for transit traffic; has to do with
dimensioning.
|
|
|
2087
|
d. Independence of work forces….. a lot comes from how workforce is
structured (geopolitical reasons).
Subnetworks and routing areas are synonymous: if we’d done things
later, we’d have included the edge also.
|
|
|
2088
|
e. Characteristics of ASON network topologies:
Not a single backbone: e.g., 2 LECS and 2 alternate service providers. Cannot make everything go through a single
backbone, as there is no single backbone, also regulatory concerns may add
requirements for local call routing policies.
|
|
|
2089
|
f. If look at network in holistic way: from
different views you see different hierarchies. Hierarchical containment important from a particular
perspective. E.g., maintenance, vs.
routing, versus restoration. Process
of routing connection, and organization of routing areas, has to be
clarified.
|
|
|
2090
|
g. If using source routing, you need to have a
routing view that contains source and destination. This view is built from information exchanged by the routing
protocols at different levels along the routing hierarchy. This must include reachability information
for all destinations that are made available to that interface. What you resolve and what you get from
somewhere else. What do you put in
the protocol as an attribute – if just a matter of keeping elements
separate. Want protocol to be passing
multiple level information, to minimize the amount of talking between
RCs. Typically, because of scoping,
would only pass two or three levels.
Myself, my children, and my parents…..? There may be an organization that makes this true. The further you’re trying to go, the more
you abstract the further away stuff. The protocol(s) must support source
routing in a network of recursive partitioning (which has been called
hierarchical routing areas).
|
|
|
2091
|
h. The main difference between in routing
approaches is whether the top level Connection Control is able to allocate
link connections on the resources it can see. Or would you aim for a link, and then allocate the link
connection when you get there. Source
and step-by-step aim do this (assuming link connections are available.) This reduces the amount of info the
enclosing level is looking at.
|
|